The Microsoft Style Guide Part 5: Punctuation
In Quack This Way, a book about language and writing by lexicographer Bryan A. Garner and writer David Foster Wallace, Wallace notes that “punctuation isn’t merely a matter of pacing or how you would read something out loud. These marks are, in fact, cues to the reader for how very quickly to organize the various phrases and clauses of the sentence so the sentence as a whole makes sense.”
For something so small as a comma or a period, punctuation plays a critical role in writing. It’s not just a formality we pick up in grade school; punctuation can make or break a written text, because it delineates writing into segments we can process and understand.
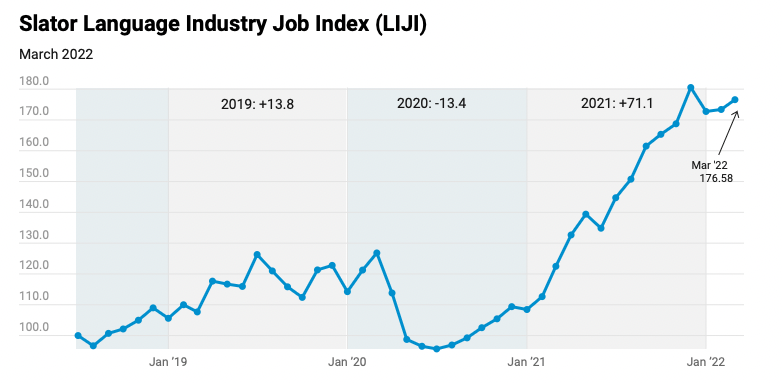
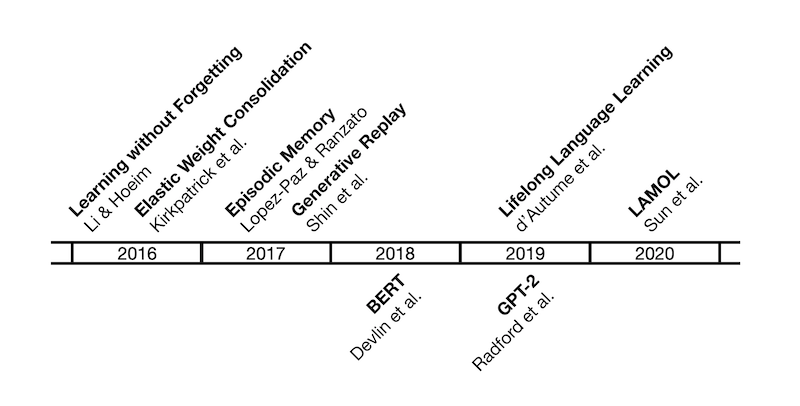
Punctuation doesn’t stop at that, however. Form and content are difficult to differentiate in good writing, and writers have taken advantage of the variety of punctuation to not only clarify their writing, but also to stylize it and give their stories life. Take this image by neurologist Adam J. Calhoun, for example:

Punctuation in Blood Meridian by Cormac McCarthy (left) and in Absalom, Absalom! by William Faulkner (right). Image credits: https://medium.com/@neuroecology/punctuation-in-novels-8f316d542ec4
Calhoun has stripped Blood Meridian and Absalom, Absalom! (phenomenal novels by Cormac McCarthy and William Faulkner, respectively) of words, leaving behind only punctuation marks. Examining only the punctuation of the novel says much about the novel.
There’s McCarthy, with his fields of periods, interspersed by the occasional question mark. We can assume, only by looking at the punctuation, that the work is a largely static and quiet one. There’s no quotation mark to be seen anywhere; modern writers do like to omit quotation marks, opting for italics instead. On the other hand, there’s Faulkner with his numerous parenthesis—some of them containing up to 5 punctuation marks inside them—and his interminable sequence of commas that seem to never end. His sentences are long and winding, fearless of nested clauses and phrases.
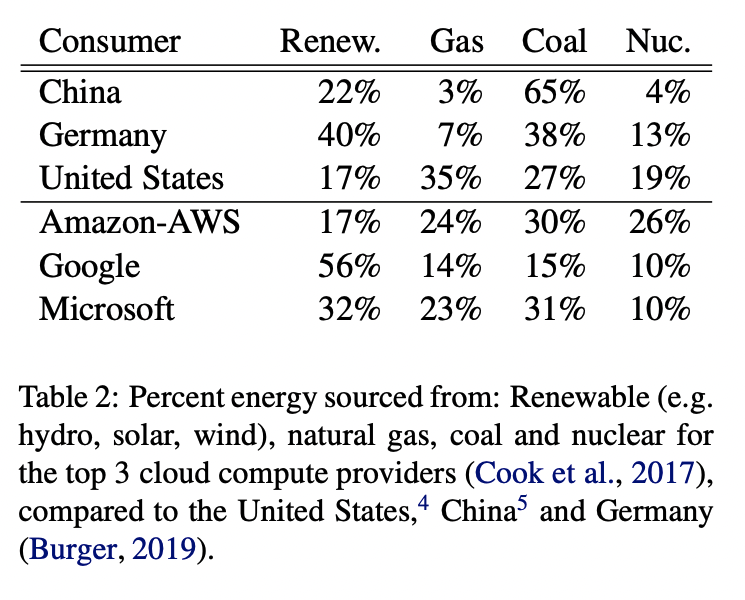
Calhoun also compares other well-known novels by the kind of quotation marks used and how often they appear:

A Farewell to Arms, for example, is chock full of quotation marks, which suggests an abundance of dialogue and conversations. Alice in Wonderland, however, boasts the most frequent usage of single quote marks. Save for Blood Meridian and A Farewell to Arms, commas are almost always the most popular punctuation of choice. This is all to say that punctuation doesn’t just sit idly by; rather, it brings a work to life. It’s an important part of writing, to say the least, and that’s why we should treat it as such.
The Microsoft Style Guide has a number of guidelines regarding the use of punctuation. Most of it is stylistic or grammatical, but conforming to these rules will help you write in that crisp, friendly, and amiable Microsoft voice that we’ve all come to love. By mastering these punctuation guides, you’ll not only be able to write more concise, logical texts, but also learn to manipulate the power of punctuation to amplify and saturate your voice with more nuance.
Apostrophes
In the English language, the apostrophe is used to form the possessive case of nouns. Unlike what many of us have been taught in grade school, the Style Guide advises adding an apostrophe and an s, “even if the noun ends in s, x, or z” to avoid confusion. After all, some words that end in -s might not always be plural; the apostrophe and the subsequent s should serve to clarify the plurality of the noun preceding them. Apostrophes are also used in the English language to form contractions. Apostrophes are used in the place of the missing word, such as in can’t, don’t, and it’s.
There are some places that apostrophes don’t really belong in—although you see them used here often, especially on the internet. Don’t use an apostrophe to write the possessive form of it; the correct word is its. Don’t use an apostrophe with possessive pronouns—your’s and their’s are incorrect. Finally, don’t use an apostrophe to form plurals.
Colons
Colons and semicolons are a tricky couple. Their usage can be difficult to differentiate at times, but the Microsoft Style Guide has some solid guidelines that might help you use them with more purpose and deliberation.
The first function of a colon is to mark the start of a list. Put a colon at the end of a phrase to introduce a list. This is straightforward enough, like in this sentence, “I love three things: coffee, tea, and freedom.”
The second function of a colon is to demarcate a statement from its expansion. Put a colon at the end of a statement when you want to follow it with a second statement that expands on the previous one. The Style Guide does remark that the colon in this function should be used sparingly. Here is Microsoft’s example: “Microsoft ActiveSync doesn’t recognize this device for one of two reasons: the device wasn’t connected properly or the device isn’t a smartphone.”
To this, the guide notes that “most of the time, two sentences are more readable.” The colon can be replaced—to greater effect—by a period. But in case you do choose to use a colon, make sure to lowercase the word the follows the colon.
There are exceptions, of course, to the lowercase rule. If you’re listing city names, capitalization is unavoidable. Plus, the third function of the colon is to introduce a direct quotation, as in: “The colon introduces a direct quotation.” In such a case, capitalizing the word after the colon is unavoidable as well.
Lastly, the fourth and final function of the colon is to demarcate the title from its subtitle, such as “Block party: Communities use Minecraft to create public spaces.”
Commas
As seen at the beginning of this post, commas are one of the most frequently used punctuation marks, followed closely by periods and single quote marks. The uses of the comma are many; it’s a flexible, multi-purpose tool, used by writers as a primary tool of demarcation and organization.
The Microsoft Style Guide lists the usual functions of the comma, which you all probably know. The comma is used when listing three or more items, like in the sentence “Outlook includes Mail, Calendar, People, and Tasks.” Note how the guide advocates the use of the Oxford or serial comma, or the comma right before the conjunction, as is to be expected by a U.S. corporation.
The comma follows an introductory phrase, which is a subordinate or dependent clauses that precedes an independent clause. Take, for example, this sentence: “With the Skype app, you can call any phone.” The comma also joins independent clauses with a conjunction. In other words, two or more independent clauses can be connected with a comma and a conjunction, like in the sentence “Select Options, and then select Enable fast saves.”
The comma is also used to replace the word and, like in the sentence “Adjust the innovative, built-in Kickstand and Type Cover.” The guide, however, does advise you to avoid this type of phrasing and opt instead for a friendlier, conversational tone.
Lastly, a formal usage of the comma that some might not know: use a comma to surround the year the writing a complete date within a sentence. Here is an example by Microsoft: “See the product reviews in the February 4, 2015, issue of the New York Times. Note how the year 2015 is surrounded by commas.
Dashes and hyphens
Dashes and hyphens often go by unnoticed in grade-school grammar lessons. In writing, the em dash (—), the en dash (–) and the hyphen (-), each with their distinct lengths, are used in different scenarios.
Em dashes are frequently used in writing for emphasis. Take, for example, this beautiful sentence by Mary Gaitskill in her novel Bad Behavior: “Because once, when I was about twelve, I was in my father’s study rubbing his neck—I used to do that all the time for him—and there was this Playboy calendar over his desk and some babe was on it and I said to him, ‘Do you like her?’ and he said, ‘Sure I do,’ and I said, ‘Would you like to meet her?’ and he looked shocked and said, ‘No, she’s just a dumb broad.”
The em dash is also used at the end of sentences, like in this sentence from Rachel Cusk’s Kudos: “There was this antique telephone on the desk and I kept wanting to call someone up and get them to come and rescue me. One day, I finally picked it up and it wasn’t connected—it was just a decoration.”
En dashes are used more for formatting, like indicating a range of numbers, such as 2015–2017, or a minus sign (12 – 3), or a negative number. En dashes also replace the hyphen in a compound modifier when “one element of the modifier is an open compound,” such as Windows 10-compatible or dialog box-type.
Lastly, hyphens. Hyphens are used to connect two or more words that precede and modify a noun as a unit. There are caveats, however. If the compound modifier makes sense and isn’t confusing without the hyphen, it’s okay not to use the hyphen. Hyphens should be used when one of the words in a compound modifier are a past or present participle (“left-aligned text,” “free-flowing form”).
We could go on for a long time discussing the uses of the hyphen, from its use in compound numerals and fractions (“twenty-fifth,” “one-third”) or confusing prefixes (“non-native,” “non-XML”). It’s important that, when writing in the Microsoft voice, you keep the guide close at hand, referring to it when necessary.
Exclamation marks and question marks
The rules for the exclamation mark (!) and the question mark (?) are simple: use them very sparingly, only when needed.
Quotation marks
The guide is very strict on the use of quotation marks—more so, perhaps, than other punctuation. After all, quotation mark usage varies across regions and countries, and as such, there is a greater need for standardization.
For example, the guide advises the following: “In most content, use double quotation marks (“ “) not single quotation marks (‘ ‘)… In printed content, use curly quotation marks(“ ”)… In online content, use straight quotation makrs.”
The guide also suggests you use the terms quotation marks, opening quotation marks, and closing quotation marks instead of quote marks, quotes, open or close quotation marks, or beginning or ending quotation marks.
Semicolons
The guide generally disapproves of semicolons. They are used mostly in writing to demarcate sentence breaks and join independent clauses. Semicolons don’t help much in speeech; after all, punctuation has more to do with the silence between the words, and it’s unclear what kind of silence or break the semicolon is supposed to signal.
But if need be, semicolons can be used. Semicolons join independent clauses without the need for a conjunction (“Select Options; then select Automatic backups.”). It also connects contrasting statements without a conjunction (“What’s considered powerful changes over time; today’s advanced feature might be commonplace tomorrow.”).
We hope you enjoyed this fifth and final part of our introduction to the Microsoft Style Guide. For writers, especially in the tech or business industry, the Microsoft Style Guide will polish and refine your writing, rendering your words more comprehensible and legible to those you wish to communicate to. It’s important to keep on practicing, making sure you follow the guidelines.