Major Academic Breakthroughs in Eliminating NLP Gender Bias
We have recently blogged about the dangers of NLP in replicating gender bias present within natural languages. The scope of the last blog was confined to major breakthroughs by Google, but there has been much research examining gender bias in NLP done by academic research groups. These researches are remarkable in their reach and originality as well, and we wish to highlight major academic research in the field today.
Christine Basta of the Universitat Politècnica de Catalunya explains the history of wrestling with gender bias within academic research. She traces the origin of the discourse to 2016, when Bolukbasi et al., composed of members from Boston University and Microsoft Research, published a paper on gender bias in word embeddings. The paper is notable for defining gender bias as “its projection on the gender direction,” or in other words, “the more the projection is, the more biased the word is.” Here is an example of words with extreme bias projections:
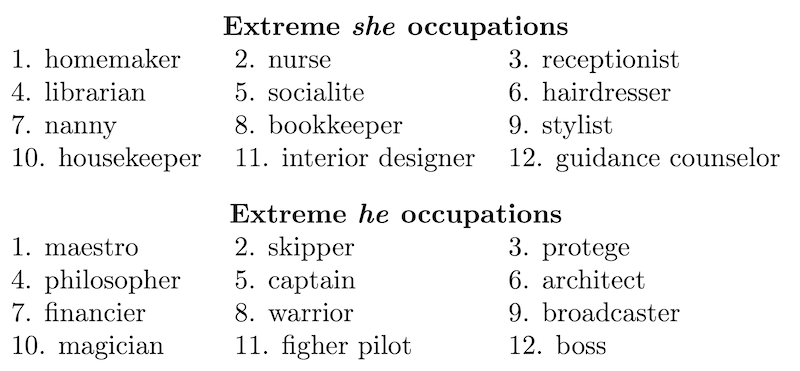
Image credit: Bolukbasi et al., “Man is to Programmer as Woman is to Homemaker?”
Bolukbasi et al. try to mitigate the bias by shortening the distance of the projection, effectively neutralizing the bias of these aforementioned words. In a 2019 paper, however, Hila Gonen and Yoav Goldberg of Bar-Ilan University reveal that simple removal methods are ineffective. Debiasing is a superficial method, they posit, noting that there is a “profound association between gendered words and stereotypes, which was not removed by the debiasing techniques.”
But progress is hardly linear; let’s backtrack to 2017, when researchers from the University of Virginia and the University of Washington came up with the RBA (reducing bias amplification) method, which puts “constraints on structured prediction to ensure that the model predictions [of images] follow the same distribution in the training data.” Constraints at the corpus-level are effective in reducing gender bias amplification, but as was said by Gonen and Goldberg, such constraints are only artificial and superficial in dealing with the unbudging association between gendered words and stereotypes.
There are other researches that accomplish similar purposes; researchers from the University of Washington have also carried out evaluations of gender bias in machine translation in 2019. The year 2018 also saw interesting research using coreferences to examine stereotyping behavior in machines. In the end, however, these researches only do well to identify problematic behavior and suggest mitigating methods that, quite frankly, don’t serve as ultimate solutions to the problem of gender bias in machine translation.
But there is still hope yet. Gonen and Goldberg’s 2019 research is particularly fascinating, as it reveals a “profound association between gendered words and stereotypes.” While all research inherently relates itself to the outside world, Gonen and Goldberg suggest that changes in algorithms will never be enough to eradicate gender bias in language. If anything, the world must change alongside machines. Machines are biased only because the natural languages of the world are biased.
Particularly fascinating is a recent 2021 paper on the current state of gender bias in MT, written by researchers from the University of Trento and the Fondazione Bruno Kessler: a paper that argues for a “unified framework,” facilitating future research. The authors note that the study of gender bias in MT is a relatively new field and briefly summarize previous analyses in the field—an important and necessary job.
This paper is more remarkable, however, for the way it reveals the very necessary connection MT has with society. “To confront bias in MT, it is vital to reach out to other disciplines that foregrounded how the socio-cultural notions of gender interact with language(s), translation, and implicit biases. Only then can we discuss the multiple factors that concur to encode and amplify gender inequalities in language technology,” writes the authors. In other words, MT research must inevitably grapple with social structures and ideology to make for a wholly unbiased translation machine.
The authors end their paper with a few hopeful directions MT could take: model debiasing, non-textual modalities, thinking beyond gender dichotomies, and more representation in the research process. These are all feasible, manageable methods and steps that make for a more nuanced and equal language model, safe from the biases that plague and corrupt human language.
The applications of this are manifold; aside from gender bias, there remains ethnic and racial bias, class bias (in the economic sense), political bias, among numerous others. Similar methodologies can be applied to eradicate these biases from MT models. Until then, human translators have the duty to ensure that no nuance is lost in translation and that their work is not affected by the biases that often encumber and muddle language.
Here at SDTS, our translators and localization experts are attentive to the ways in which machine translation iterates bias; we make sure our solutions are bias-free and inclusive. If you’re looking for a translation and localization service, give SDTS a try: our team of translators and localization experts ensure that your translations are of the utmost integrity and accuracy.
References
https://arxiv.org/pdf/1607.06520.pdf https://arxiv.org/pdf/2104.06001.pdf https://mt.cs.upc.edu/2021/03/29/major-breakthroughs-in-gender-bias-in-nlp-vii/