Meta to the Rescue: New Projects for Translation Models Announced
Meta (formerly known as Facebook) has just announced that they will be investing in research for a universal speech translator and a new advanced AI model for low-resource languages. The news comes some three months after Meta’s translation model beat out other models at the 2021 Conference for Machine Translation.
The tech giant’s devotion to translation is heartwarming—and sorely needed. For people who speak one of the major languages of the world—English, Spanish, Mandarin—translation is no big deal; many high-quality translation programs are available online for speakers of these languages. At the same time, there are billions of people out there who cannot access the abundance of information available on the internet, merely on the basis of their native tongue. Advances in machine translation can help bridge these gaps and eliminate barriers in communication. Meta claims that these developments will “also fundamentally change the way people in the world connect and share ideas.”
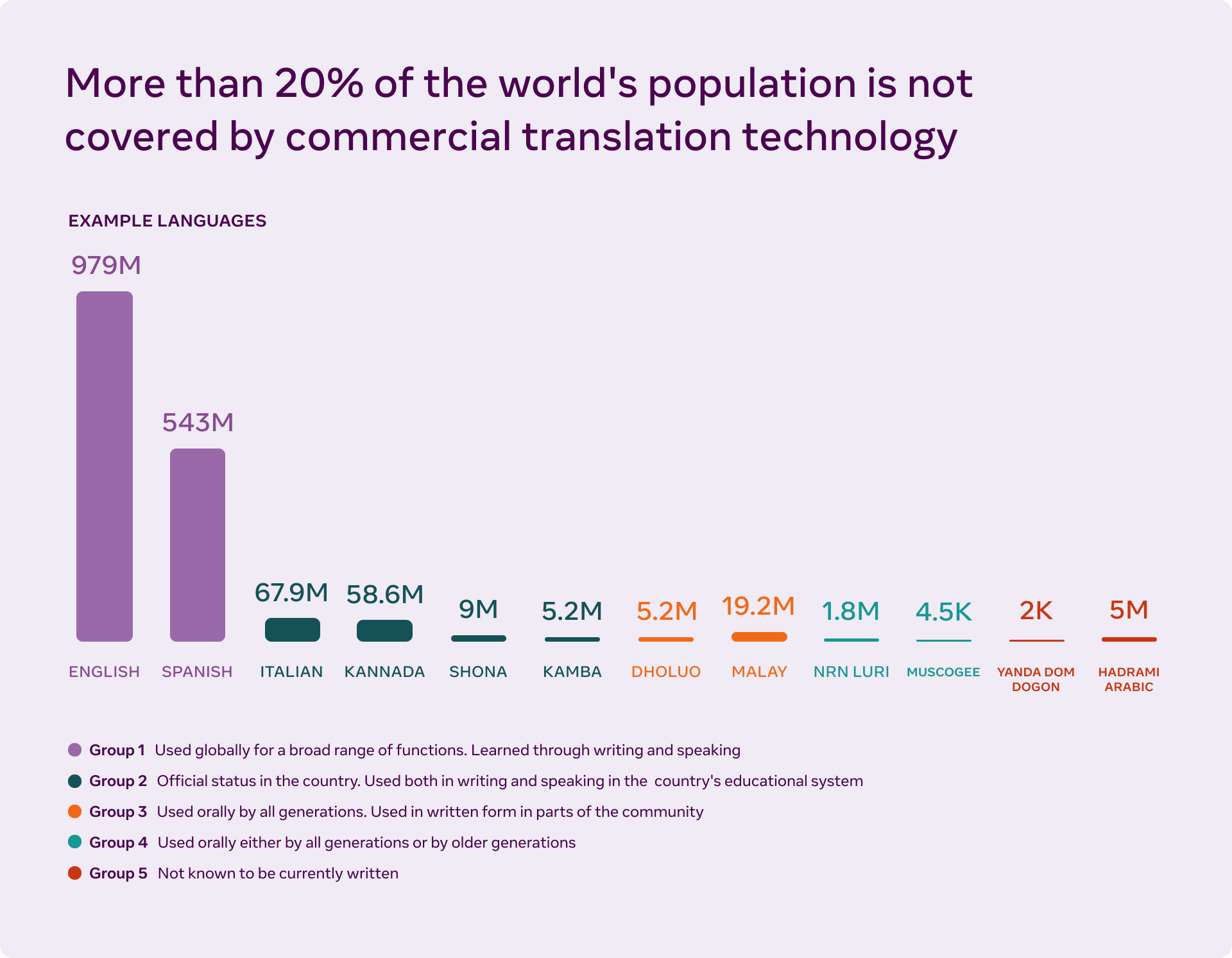
Image credits: Meta AI, “Teaching AI to translate 100s of spoken and written languages in real time”
But the path to universal communication isn’t quite so easy. The problem with MT systems today is that they don’t work well for low-resource languages, as there simply isn’t enough training data. Meta lists three major hurdles in perfecting machine translation: overcoming data scarcity by acquiring more training data in more languages; overcoming modeling challenges that will arise as models scale to accommodate more and more languages; and finding new ways to evaluate and improve on results.
Problem 1: Data Scarcity
Data scarcity is perhaps the greatest of machine translation’s problems, especially for languages that are not spoken by many people, and all the more so for languages that don’t have written scripts. MT development currently relies heavily on sentence data for improving text translations; as a result, only languages with plenty of text data (English, Spanish, etc.) have been the focus of MT development.
This is even more of a problem for direct speech-to-speech translation. Speech-to-speech translation is more limited in its capacity than text translations, as the former most frequently utilizes text as an intermediary step (speech is transcribed in the source language into text, translated into the target language, and then input into a text-to-speech system for audio generation.) This dependency on text greatly inhibits speech-to-speech translation’s efficiency, not to mention the sheer lack of speech recordings to utilize as analyzable data.
Problem 2: Scaling
The second challenge for MT development is to overcome modeling challenges as MT systems grow bigger and bigger to accommodate more languages. So far, many MT systems have approached translation from a bilingual perspective, utilizing separate models for each language pair (such as English-Russian or Japanese-Spanish, for example). While bilingual models work well as a single model, it is unrealistic to utilize thousands of different models for the thousands of languages in the world; we can’t simply create a new model every time we need translations for a different language pair.
Translation research has been looking into ways to overcome these limitations; recent developments reveal that multilingual approaches—not bilingual—are more efficient at handling larger combinations of language pairs. Multilingual models are simpler, more scalable, and better for low-resource languages; until recently, multilingual models couldn’t match bilingual model performance for high-resource languages such as English and Spanish, but that is no longer the case. Meta’s translation model that outperformed other models at the 2021 WMT—that was a multilingual model, too. For the first time, a single multilingual model has outperformed bilingual models in 10 of 14 language pairs, including both low- and high-resource languages. We have a long way to go, however; Meta notes that “it has been tremendously difficult to incorporate many languages into a single efficient, high-performance multilingual model that has the capacity to represent all languages.”
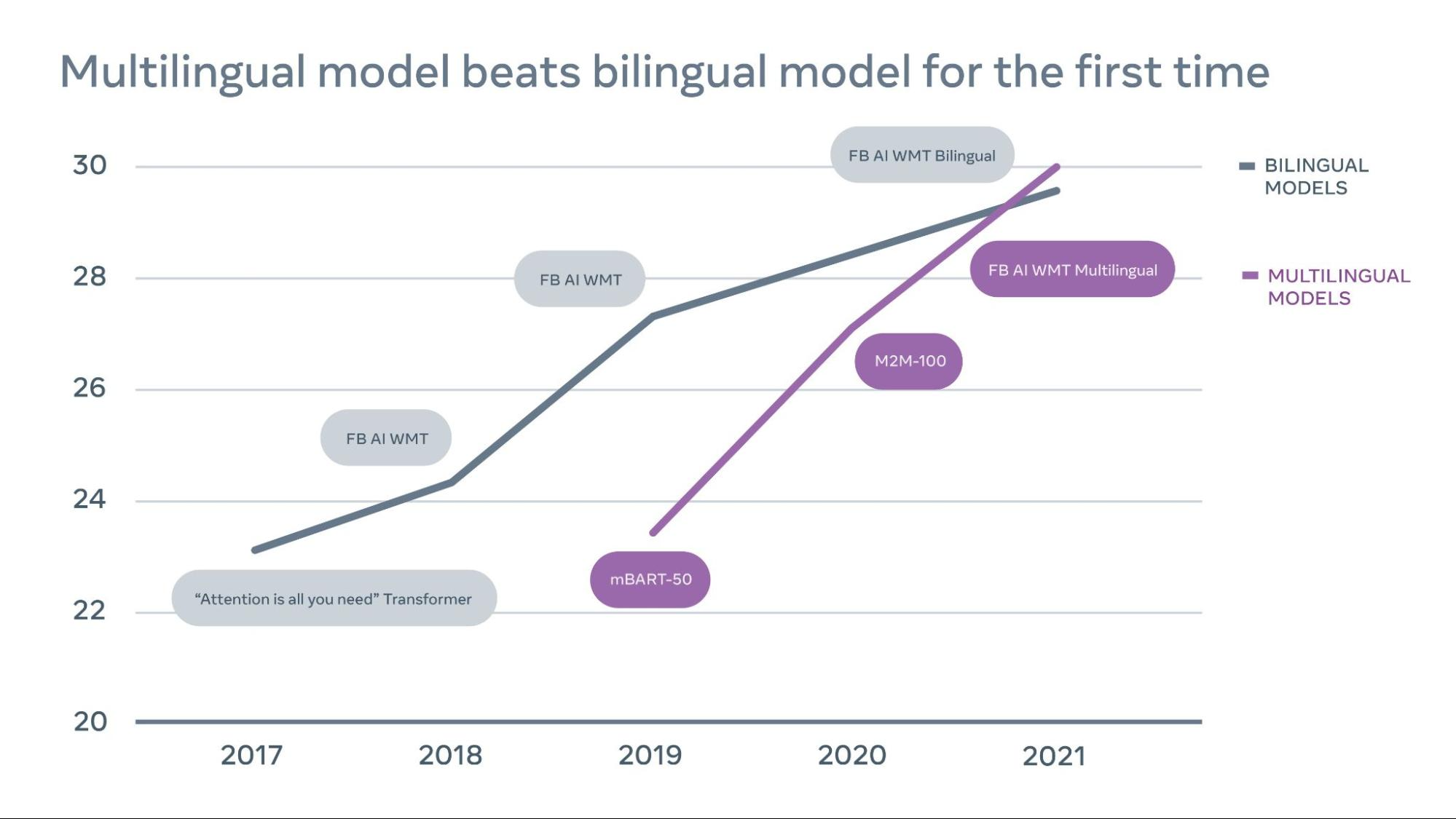
Image credits: Meta AI, “The first-ever multilingual model to win WMT, beating out bilingual models”
For real-time speech-to-speech MT models, the same challenges remain alongside an additional difficulty: latency problems. Latency here refers to the lag in real-time translation; this is one problem that must be overcome before speech-to-speech translation can be used effectively. A major reason behind latency problems is varying word order in languages; professional simultaneous interpreters also struggle with this problem (with average latency time being around three seconds for human professionals). Meta provides this example for understanding latency problems:
Consider a sentence in German, “Ich möchte alle Sprachen übersetzen,” and its equivalent in Spanish, “Quisiera traducir todos los idiomas.” Both mean “I would like to translate all languages.” But translating from German to English in real time would be more challenging because the verb “translate” appears at the end of the sentence, while the word order in Spanish and English is similar.
Problem 3: Result Evaluation
A crucial part of developing MT translation is evaluation; it’s a step many people tend to overlook, but machines, like human translators, need feedback to improve. While evaluation models and standards exist for popular language pairs (e.g. English to Russian), such standards aren’t readily available for more obscure language pairs (e.g. Amharic to Kazakh). Like the transition from bilingual to multilingual models, we need to start thinking of multilingual, comprehensive, and one-for-all evaluation methods, so that we can evaluate MT system performance for accuracy and make sure translations are carried out responsibly. Such evaluation should include making sure MT systems preserve cultural sensitivities and do not amplify biases present within natural languages.
The main question now is: how do we overcome these three challenges specific to MT translation development? Thankfully, Meta also has answers to these questions; while their answers are still largely hypothetical, they have plenty of previous data and research to back up their answers.
Solution 1: Managing Data Scarcity
Meta’s answer to the problem of data scarcity is to expand its automatic data set creation techniques. For this, Meta brings in the LASER toolkit, short for Language-Agnostic SEntence Representations; LASER is an open-source, massively multilingual toolkit that converts sentences of various languages into a single multilingual representation. Afterward, a large-scale multilingual similarity search is carried out to identify sentences that have a similar representation.

A graphic illustrating the relationships automatically discovered by LASER between various languages. Note how they correspond to the language families manually defined by linguists. Image and caption credits: Meta AI, “Zero-shot transfer across 93 languages: Open-sourcing enhanced LASER library”
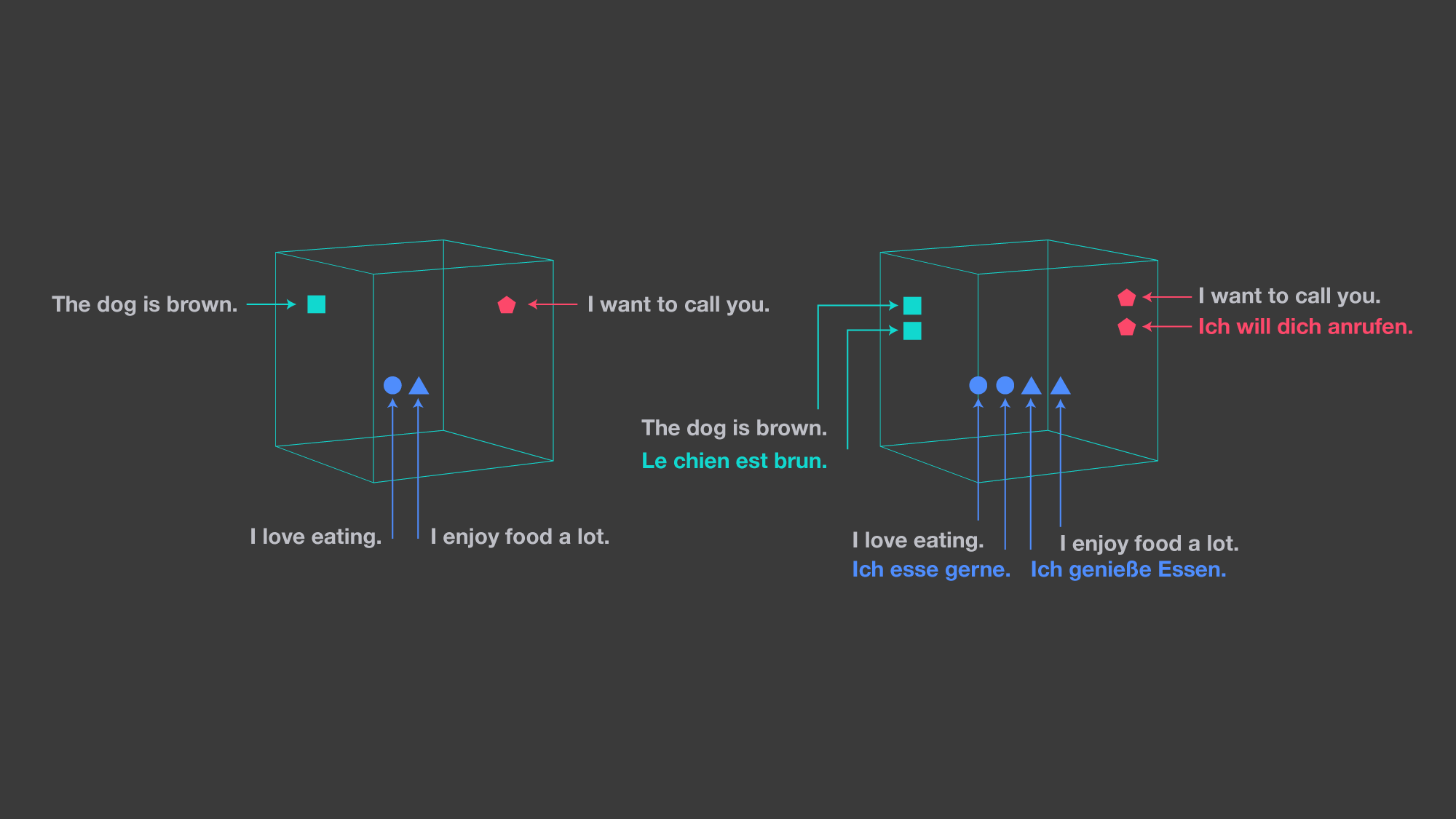
The image on the left shows a monolingual embedding space, whereas the one on the right illustrates LASER’s approach, embedding all languages in a single, shared space. Image and caption credits: Meta AI, “Zero-shot transfer across 93 languages: Open-sourcing enhanced LASER library”

A table illustrating how LASER was able to determine relationships between sentences in different languages. Image and caption credits: Meta AI, “Zero-shot transfer across 93 languages: Open-sourcing enhanced LASER library”
Using LASER, Meta has developed systems such as ccMatrix and ccAligned, programs that are capable of finding parallel texts online. LASER is also capable of focusing on specific language subgroups (such as the Bantu languages) and learning from smaller data sets. The possibilities of LASER are endless, as it allows for seamless, surefire scaling across a wide expanse of languages. The possibilities don’t end there; recently, Meta has extended LASER to work with speech as well; they have already identified nearly 1,400 hours of aligned speech in English, Spanish, German, and French.
Solution 2: Building More Capable Models
Meta is also working to improve model capacity so that multilingual models can perform better even when scaled to accommodate more languages. Current MT systems suffer from performance issues, which lead to inaccuracies in text and speech translation; this is because current MT systems work within a single modality and across a select few languages. Meta hopes for a future in which translations work faster and more seamlessly, whether it’s going from speech to text, text to speech, text to text, or speech to speech.
To achieve this goal, Meta is investing heavily in creating larger, more robust models that train better and function more efficiently, learning to route automatically so as to balance high-resource and low-resource translation performance. Meta talks of their recent development of M2M-100, the first multilingual machine translation model that is not based on English. By eliminating English as the working intermediary language, translations from one non-English language to another become more fluid and efficient, allowing translation to achieve the same level of customized bilingual systems with even more language pairs.
As for latency problems, Meta is currently working on a speech-to-speech translation system that “does not rely on generating an intermediate textual representation during inference”; such a paradigm has been shown to be faster than a “traditional cascaded system that combines separate speech recognition, machine translation, and speech synthesis models.”
Solution 3: Coming Up with New Evaluation Models
Evaluation, the important step in MT development that it is, still has a long way to go in the context of massively multilingual translation models. After all, we need to know whether certain developments in MT are actively producing better data, models, and outputs. Meta notes that evaluating large-scale multilingual model performance is a tricky job, as it is a “time-consuming, resource intensive, and often impractical” challenge.
To this end, Meta has created FLORES-101: the first multilingual translation evaluation data sets covering 101 languages; FLORES-101 allows researchers to rapidly test and improve multilingual translation models by quantifying the performance of systems through any language direction. While FLORES-101 is still in the process of development in collaboration with other research groups, FLORES-101 is a critical part of a well-functioning massively multilingual model.
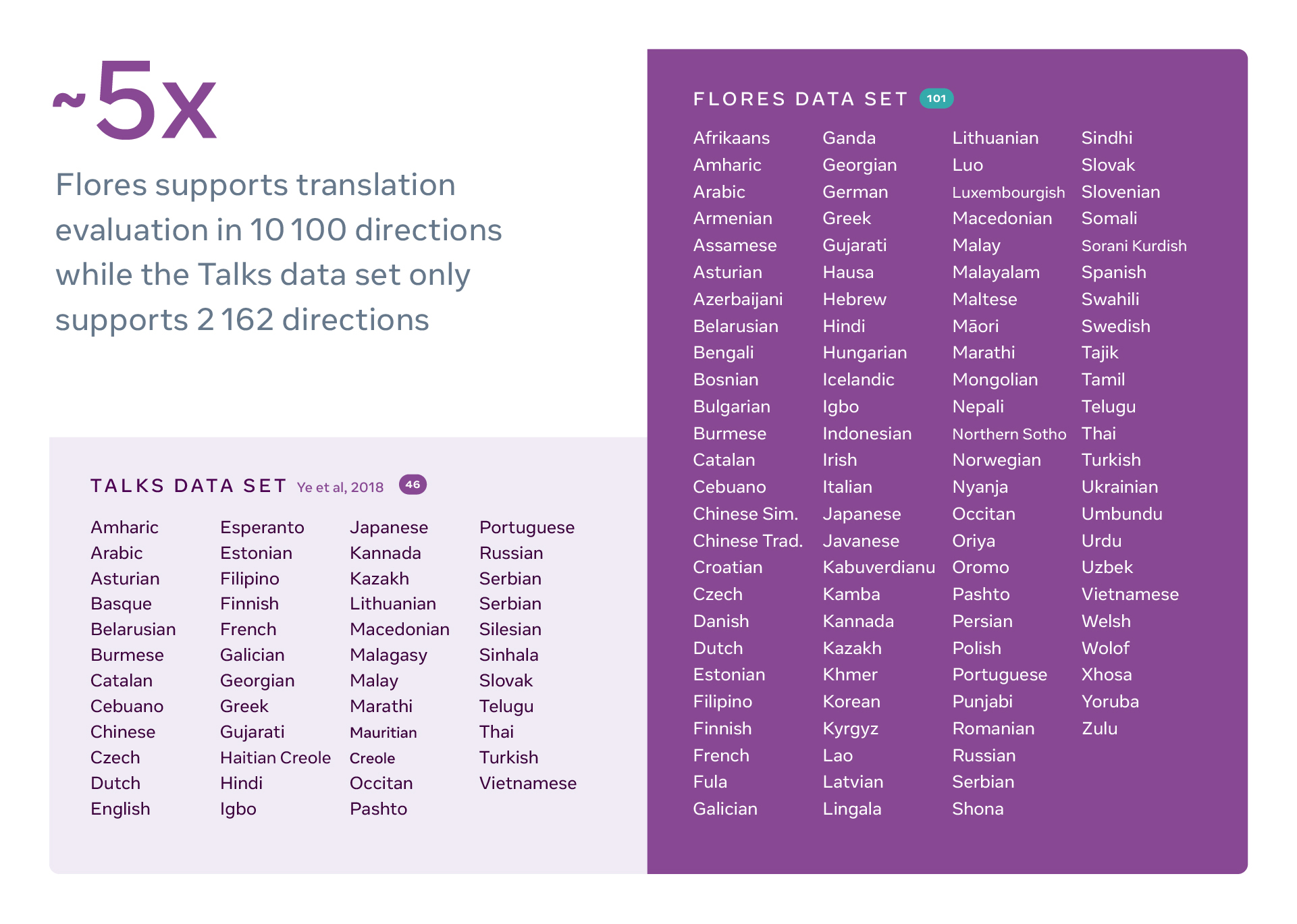
The FLORES data set compared to the Talks data set. Image credits: Meta AI, “The FLORES-101 data set: Helping build better translation systems around the world”
Meta’s vision of a connected future is grandiose and visionary. Meta claims that such developments will “open up the digital and physical worlds in ways previously not possible,” as the company slowly removes barriers to universal translation for a majority of the world’s population. Meta should be lauded for their inclusive, collaborative efforts; the company open-sources their work in corpus creation, multilingual modeling, and evaluation so that other researchers can join in their efforts. After all, if Meta’s mission is to open the world up to free, unlimited communication, it only makes sense that their efforts are also based on collaboration and communication with external researchers to accomplish their dreams.
But the last paragraph of Meta’s announcement is particularly beautiful:
Our ability to communicate is one of the most fundamental aspects of being human. Technologies — from the printing press to video chat — have often transformed our ways of communicating and sharing ideas. The power of these and other technologies will be extended when they can work in the same way for billions of people around the world — giving them similar access to information and letting them communicate with a much wider audience, regardless of the languages they speak or write. As we strive for a more inclusive and connected world, it’ll be even more important to break down existing barriers to information and opportunity by empowering people in their chosen languages.
As one of the world’s leading tech groups, Meta has the power and duty, among other things, to invest its resources in making the world a more connected place. The dream of a completely connected world: that is the direction of technology, and machine translation lies at the heart of it.
References
https://ai.facebook.com/blog/teaching-ai-to-translate-100s-of-spoken-and-written-languages-in-real-time
https://ai.facebook.com/blog/laser-multilingual-sentence-embeddings/
https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
https://ai.facebook.com/research/publications/ccaligned-a-massive-collection-of-cross-lingual-web-document-pairs/
https://ai.facebook.com/blog/introducing-many-to-many-multilingual-machine-translation/
https://ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
https://ai.facebook.com/blog/the-flores-101-data-set-helping-build-better-translation-systems-around-the-world/