Lifelong Learning Systems: the Frontier of AI-Powered Machine Translation
As of now, there isn’t much that separates humans from machines. But the few differences that remain are big discrepancies that have to do with the lived experience of humans, as well as the ontological differences that markedly differentiate us from our creations. These are things like free will (arguably), understanding, or emotion. Save for these human characteristics, machines might outpace us by far—they’re capable of running calculations and all sorts of incredible tasks at speeds no human would dare to dream of.
Another main difference between a human and a machine is that the former retains with them a (nearly) lifelong account of their memories. While memory does thin out the further back we recount, our capacity to retain memory is comparatively better than that of a machine system. This is particularly an issue with modern machines; neural network-based models, according to UPC’s Magdalena Biesialska, “learn in isolation, and are not able to effectively learn new information without forgetting previously acquired knowledge.” As the standard base model for modern translation engines, neural network-based models lie at the heart of the quest for better machine translation.
This apparent debilitation in neural network machines has prompted—in the last decade or so—a study into machine memories. Specifically, researchers are keen to discover methods through which neural network machines can more efficiently access previous knowledge, much like how a human would. Here is the timeline of the history of lifelong learning research:
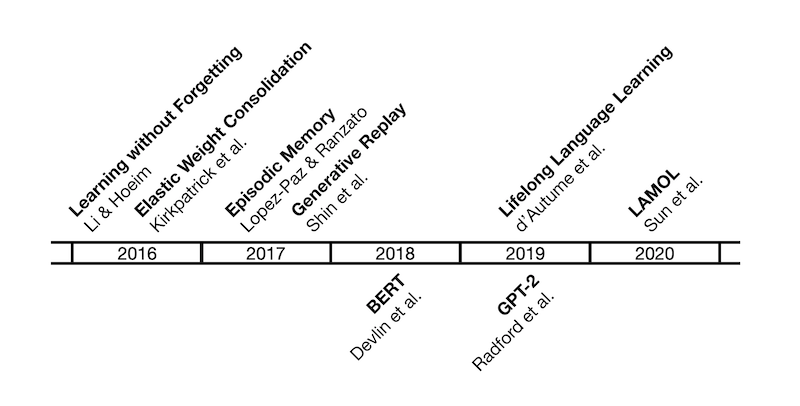
Image credit: Magdalena Biesialska, “Major Breakthroughs in Lifelong Learning“
The research into lifelong machine learning is to emulate human learning in machines, human learning being a continuous effort to learn and adapt to new environments and utilizing this accumulated knowledge to future problems. In other words, machines, with enough development in this area, “should be able to discover new tasks and learn on the job in open environments in a self-supervised manner.” UIC professor Bing Liu emphasizes the necessity of such lifelong learning; without it, Liu says, “AI systems will probably never be truly intelligent.”
This brings us to 2016 when Zhihong Li and Derek Hoiem of the University of Illinois at Urbana-Champaign published one of the first works in the field of LLL in the context of deep learning. Li and Hoiem introduce the concept of Learning without Forgetting (LwF), which “uses only new task data to train the network while preserving the original capabilities.” Previously learned knowledge is “distilled” (AKA distillation loss) to maintain performance, but at the same time, prior training data is not necessary. Biesialska explains it in simpler words: “first the model freezes the parameters of old tasks and trains solely the new ones. Afterward, all network parameters are trained jointly.” This way, the neural network is less likely to suffer from amnesia—catastrophic forgetting, in computer lingo—but LwF is limited in the kinds of new tasks the machine can learn.
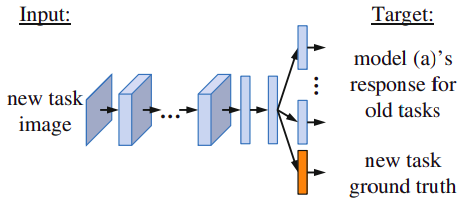
Image credit: Li and Hoiem, “Learning without Forgetting“
The same year, UK-based AI research lab DeepMind and the bioengineering department of Imperial College London collaborated on coming up with a new solution to catastrophic forgetting. Their approach is labeled Elastic Weight Consolidation; unlike LwF, which utilizes knowledge distillation to prevent catastrophic forgetting, EWC “remembers old tasks by selectively slowing down learning on the weights important for those tasks.” Parameters are constrained for previously learned algorithms that perform similar operations to that of the new task, mimicking human synaptic consolidation.
A year later, in 2017, David Lopez-Paz and Marc’Aurelio Ranzato from the Facebook Artificial Intelligence Research published their research on Gradient Episodic Memory. Unlike the previous two methods—which are considered to be regularization methods—GEM alleviates catastrophic forgetting through routine partial storage of data from past tasks. Not only is their research GEM important, but Lopez-Paz and Ranzato are also lauded for their threefold metrics, which evaluate the efficiency and productivity of a GEM-based machine.
2017 also saw the introduction of generative replay in a paper published by Shin et al.; generative replay is an alternative method of storing old data in which pseudo-samples are created, stored, and utilized for future tasks. Biesialska notes that “although the GR method shows good results, it… [is] notoriously difficult to train.”
How does all this relate to actual language learning, processing, and translation? All the previous research coalesced into a landmark research case in 2019 by members of DeepMind, titled “Episodic Memory in Lifelong Language Learning,” which combines previous approaches to lifelong learning and applies them to natural language processing.
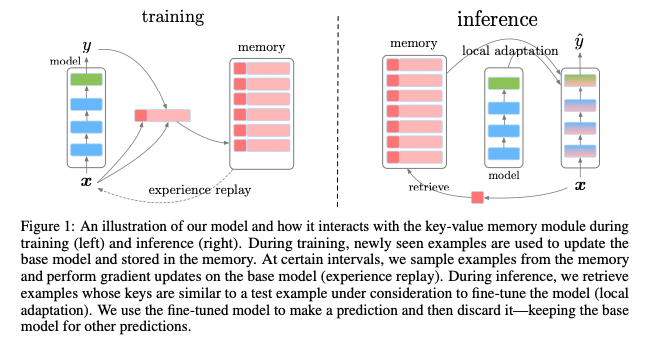
Image credit: d’Autumne et al., “Episodic Memory in Lifelong Language Learning“
In short, this 2019 research investigates how an episodic memory model with “sparse experience replay” and “local adaptation” learns continuously and reuses previously acquired knowledge. While lifelong learning is still a budding area of interest and has yet to show any widespread usage among the general public, these kinds of research illustrate the possible developments in machine translation as neural machine translation overcomes catastrophic forgetting.
In a survey of lifelong learning in natural language processing, Biesialska et al. point out the current limitations on developments in NLP. Machines are not yet able to work with partial data as humans do; machines struggle with systematic generalization about high-level language concepts. However, the authors remain hopeful about the future of lifelong learning in language processing; previous research has honed methodology down to a science and has thus made future developments more promising.
These advances in machine memory are not synonymous with complete human parity; machines have a long way to go before they can think of besting us at the thinking game. But until then, machines can better help translators do their jobs. With lifelong memory and enhanced memory storage and referral processes, neural network-based models perform better “text classification and question answering.” These functions will hopefully allow the machine to approach the source text with more information and analytic functions, taking some of the burden off of the human translator.
A future with lifelong learning translation machines seems within reach. Neural machine translation will no longer be fettered by memory constraints, allowing neural networks to reach back to years and years of data to synthesize more human, contextually and historically aware translations.
References
https://www.cs.uic.edu/~liub/lifelong-learning.html https://arxiv.org/pdf/1606.09282.pdf https://arxiv.org/pdf/1612.00796.pdf https://arxiv.org/pdf/1906.01076.pdf https://arxiv.org/pdf/2012.09823.pdf https://mt.cs.upc.edu/2021/04/12/major-breakthroughs-in-lifelong-learning-viii/