New Post-Editing Paradigm Ties for Best Paper at ACL 2022
The North American Chapter of the Association for Computational Linguistics will host its 2022 Annual Conference taking place this year in a hybrid format—both online and in-person in Seattle, Washington. The conference will be taking place from July 10 to 15 and will be bringing together researchers and scientists in the computational linguistics, natural language processing, and machine translation fields from all over North, Central, and South America. The conference features tutorial sessions, workshops, and a variety of talks and sessions regarding the numerous topics within the aforementioned fields of study.
Hundreds of papers, long and short, were accepted by NAACL; of them, “Automatic Correction of Human Translations” written by Berkeley researchers and translators at Lilt Services tied for the best new task paper and won best new resource paper. Today, Sprok DTS would like to introduce some of the findings outlined in this paper, as we believe that the research carried out by these scholars and translators will greatly impact the course of machine translation as we know it.
Automatic Correction of Human Translations
Authors: Jessy Lin, Geza Kovacs, Aditya Shastry, Joern Wuebker, John DeNero
We are already familiar with the notion of post-editing, or automatic post-editing (APE), in which human translators are tasked with correcting machine-powered translations. While post-editing is believed to reduce the time spent translating and thus has been adopted as a genuine translation service worldwide, the authors of the paper point out an important fact: “a tremendous amount of translated content in the world is still written by humans.” And while we believe human translation to be nearly perfect and fluent, that is often not the case as human translators also “do make errors, including spelling, grammar, and translation errors.”
Lin et al. in their paper “Automatic Correction of Human Translation” introduce the idea of “translation error correction” (TEC), which reverses the role of the human and machine in a traditional APE setting, instead assigning machines with the task of correcting a translation completed by a human translator. This flipped paradigm more accurately depicts the role of human translators as bearing the brunt of translation work. TEC not only poses a new paradigm of effective, efficient translation but also examines the current state of development in the field of machine translation, seeing how far we’ve come in enabling a machine to enhance and improve our writing.
In short, Lin et al.’s paper consists of four parts. First, the authors release ACED, “the first corpus for TEC containing three datasets of human translations and revisions generated naturally from a commercial translation workflow.” Then, the authors utilize ACED to analyze the types of errors that human translators make. Third, the authors train TEC, adjusting the corpus so that the types of errors shown are more human-like in nature. Lastly, the TEC model is evaluated in its usability via a human-in-the-loop user study. In doing so, the authors empirically prove that TEC is a novel, quasi-viable method of machine translation.
The ACED Corpus
One of the paper’s strengths is that it offers a whole new corpus; given its inquiry into human-made errors, the corpus is a real-world benchmark, “containing naturalistic data from a task humans perform, rather than manually annotated data.” The translations in the corpus were carried out by professional translations at Lilt, a localization service provider; all the translators involved in the paper have at least 5 years of experience under their belts.
The authors note that the ACED corpus is diverse. The corpus consists of data from three accounts, each from a different domain and exhibiting different kinds of errors and difficulties. There is the ASICS dataset, which is primarily marketing material for ASICS, complete with product names and the like. The second is the EMERSON dataset, which includes industrial product names and vocabulary in the manufacturing domain. The third is the DO dataset, which are translations of software engineering tutorials.
Error Classification
The authors classify the human errors/edits present in the dataset into three major categories: monolingual edits, bilingual edits, and preferential edits. Monolingual edits are “identifiable from only the target-side text,” and include typos, grammar, and fluency errors as subcategories. Bilingual edits deal with “mismatches between the source and target text,” such as mistranslations and omissions. Preferential edits are more nuanced edits, marked as “inconsistent with the preferences of the customer” and include terminology or stylistic preferences.

Image credits: “Automatic Correction of Human Translations”
TEC is different from previous research, the authors claim, because concerns itself with error correction, not error detection and quality estimation. After annotating error labels for the three datasets (random samples except for ASICS, which was evaluated in full), the percentage of each error type was calculated. Compared to APE, in which 74% of sentences are marked as having a fluency error, only 22% of the ACED corpus are marked as such; instead, ACED features more monolingual grammar, bilingual, and preferential errors which are “notably underrepresented in APE.” It is true; APE is mainly geared toward improving the fluency of a text, as human translators are grappling with the rather machine-like translationese of MT. TEC is substantially different in this aspect, as human translations are more prone to humanlike errors—grammar, word usage, and omission.
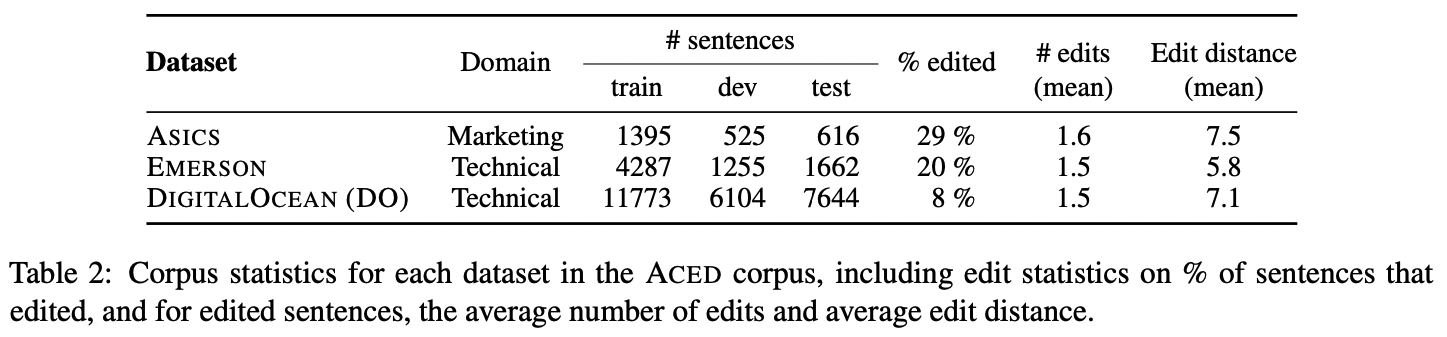
Image credits: “Automatic Correction of Human Translations”
Building a TEC Model
Now comes the technical part: the authors propose a TEC model and compare it to other models that are “designed for related tasks,” so as to “determine whether they are also effective for TEC.” All the models are designed to use the Transformer neural architecture, and are “trained on 36M sentences from the WMT18 translation task.” The authors also use a “joint English-German vocabulary with 33k byte pair encoding subwords.”
Specifically, the authors employ 5 models total for this research: TEC (the premise of this research), MT, GEC, APE, and BERT-APE. Each model is configured slightly differently. For example, the English-German neural machine translation model is trained and fine-tuned on only the source and revised translation, omitting the original translation. The encoder-decoder (monolingual) GEC model utilizes a process that corrupts the revised translation, ignoring the source sentence. APE and BERT-APE are also built, modeled, and processed differently in their own ways, making ample use of the three parts of ACED’s data tuple: the source sentence, the original translation, and the revised translation.
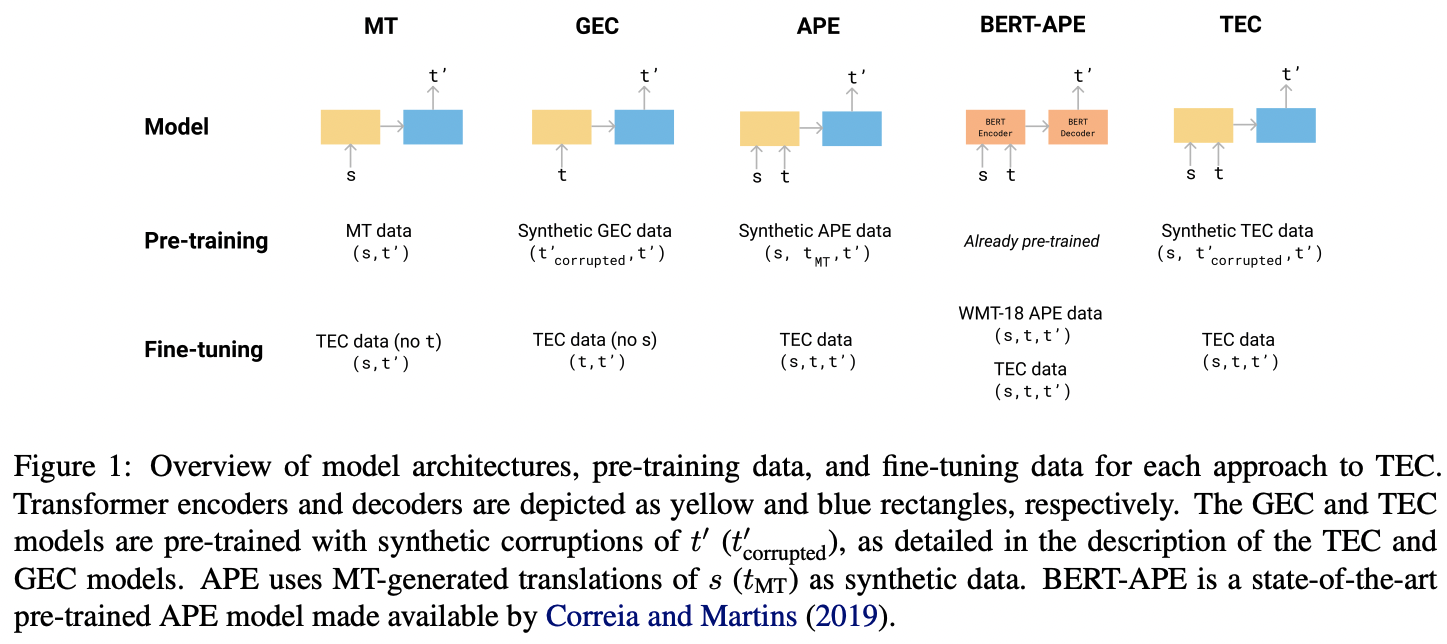
Image credits: “Automatic Correction of Human Translations.” Here, s refers to the source text, t to the original translation, and t’ to the revised translation.
The Results
The authors utilize MaxMatch scores (M2) to score the performances of the models. M2 is a “standard metric for GEC that aligns” the original translation and the edited translation to “extract discrete “edits.”” When rated using M2, TEC exhibits the best overall score on all datasets. The MT model and the GEC model both underperform. Despite their structural similarities, TEC and APE show a large difference in performance. As for the BERT-APE model—which is “first fined-tuned to achieve state-of-the-art on APE before fine-tuning on ACED”—scores low, as it makes one too many edits, leading to low precision. In sum, the authors conclude that their “results emphasize that models that excel at correcting machine errors cannot be assumed to work well on human translations.”
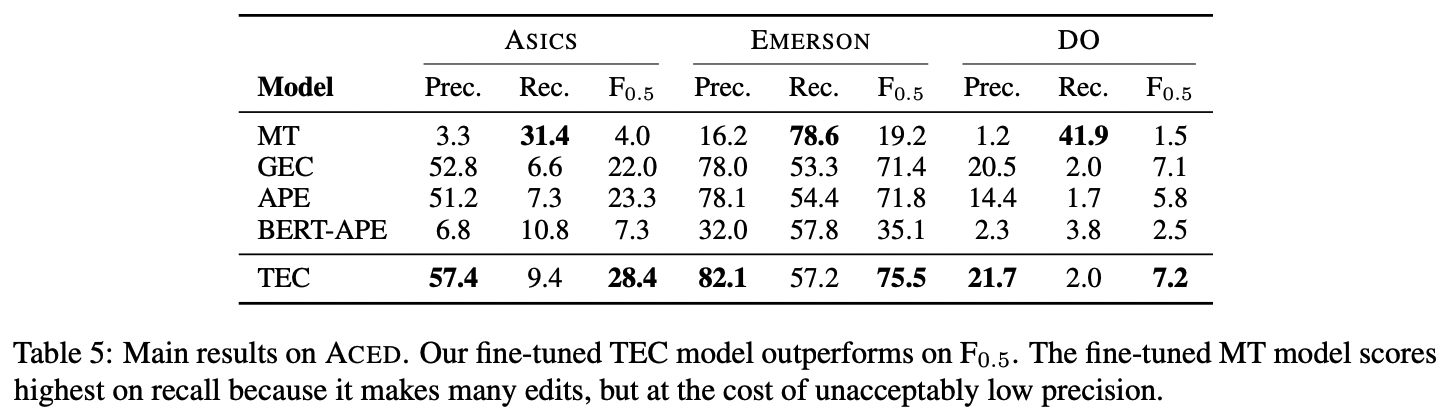
Image credits: “Automatic Correction of Human Translations.” Note the high performances outlined in bold.
The authors carry out another analysis, this time of the fluency and “per-category errors” using the ASICS dataset. The analysis is designed to calculate “overall sentence-level accuracy” and the “accuracy per error type.” For these analyses, the TEC model also “achieves the best score overall on both alternative metrics over all sentences,” although “various models outperform on specific error types.”
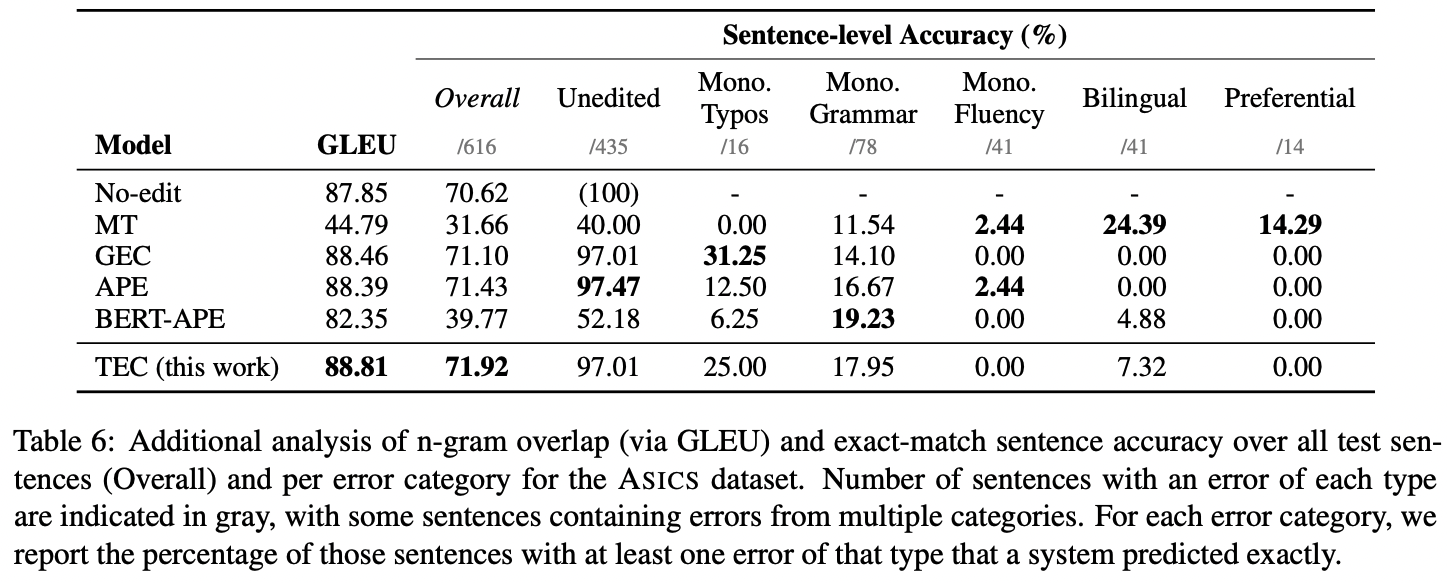
Image credits: “Automatic Correction of Human Translations.” Note the high performance scores outlined in bold.
The User Study
In the last part of the research, Lin et al. profess their interest in the feasibility of TEC as a practical system. After all, all this research will have no use if it is not significantly helpful in aiding human translators with their jobs. The authors design an interface that integrates their TEC model into a more applicable setting.
First, they had 9 professional translators familiarize themselves with the jargon of the ASICS data set, then were each assigned 74 sentences to look over. Half of the assigned sentences provided an editing suggestion by TEC, and the other half was left unsupervised to be translated directly by the human translator.

Image credits: “Automatic Correction of Human Translations”
The authors then analyzed the following:
1. Whether the TEC suggestion, if shown, was accepted or declined
2. Total time spent reviewing each sentence
3. Number of edit operations (insertions and deletions) the user made
4. Levenshtein edit distance from the original text to the final text
The results showed that “79%” of the TEC suggestions were accepted. The authors found that, when suggestions are shown to the translators, the review time is “significantly less on sentences where the reviewers accepted the suggestion, compared to sentences where they declined.” This can perhaps be explained, the authors claim, by the possibility that incorrect revision suggestions by TEC distract and slow down translators. Furthermore, there is a “significant reduction in the number of insertions+deletions” when the suggestions are shown, which could possibly mean that the “TEC system suggestions help to significantly reduce the amount of manual typing that the user must perform.”
The 9 translators were also surveyed on their experience with and opinions of the TEC system. Five of the reviewers commented that “reliability is critical”; some of the TEC suggestions were incorrect, leading the translator to double-check for other errors, consequently wasting time. Three reviewers expressed their wish of developing the use case of TEC to include that of a “memory aid or substitute for researching client-specific requirements.” One translator noted that TEC could be used as an instructive tool.
The Best Paper Committee expressed their high regard for this paper, especially impressed with the way the paper “introduces a new corpus, describes a new task, and proposes a new way of leveraging advances in NLP to support stakeholders in the (human) translation workforce.” The committee also appreciated the “in-depth usability study that showed how participatory design and evaluation can contribute to more wide-spread adoption of NLP-assisted technologies.”
References:
https://arxiv.org/abs/2206.08593
https://2022.naacl.org/blog/best-papers/