Two ACL 2022 Papers that Combat Gender Bias in Machine Translation
Gender bias is a serious problem afflicting NLP and MT today. Given the inequalities of the world (not necessarily limited to gender in this sense, but also racial, class-wise, etc.) the machines we create take after our flaws, learning and internalizing much of the hatred we exhibit on a daily basis. We covered gender bias a few weeks back, introducing major articles that deal with gender bias. Today, we are delving into two papers that explicitly cover gender and other biases in machine translation, chosen from the wide pool of amazing research topics introduced at the ACL 2022.
Measuring and Mitigating Name Biases in Neural Machine Translation
Authors: Jun Wang, Benjamin I. P. Rubinstein, Trevor Cohn
Bias exists in machine translation in many forms: gender, racial, positional, etc. One previously uncovered area of bias is name bias, in which machines wrongly infer gender and other categorical information based on a person’s name. The authors note how “leading systems are particularly poor at [estimating the gender of names] and come up with a method that can help mitigate such biases in neural machine translation.
The reason for such gendered or name bias is the fact that a major portion of textual corpora used to train language models deal with men; sample sentences dealing with women are few. In the past three years, there has been research into how “NMT systems can still be biased even when there are explicit gender pronouns in the input sentences,” which goes to show how skewed NMTs can be in their identification of genders. All this leads to the fact—which the results of this paper prove—that “NMT systems often mistake female names for males, but the reverse is rarely seen.”
What are the consequences of such misgendering? The authors note that, “as an important category of named entity, person names are particularly sensitive to translation errors since they refer to real-world individuals, and systematic biases may cause serious distress to users, and reputational damage, libel or other legal consequences for vendors.” In a world that’s becoming more reliant on machine translation by the day (unrevised machine translation of news articles is now a common practice in many media outlets, for example), the skewing of genders to favor he/him pronouns instead of she/her makes for an inaccurate, harmful depiction of the world in which all major decision-makers and subjects are male, to the exclusion of women.
This problem is especially malignant in “languages with rich grammatical gender” such as German, which would translate the English sentence “[PER] is a Royal Designer” as “[PER] ist ein königlicher Designer” if the subject were male or “[PER] ist eine königliche Designerin” if the subject were female.

Previous research has focused mostly on gender pronouns (he, she, they, etc.), which NMT still has a hard time processing. Such a problem is compounded when it comes to names, which are, at face value, devoid of immediate gender markers. For names, “gender is not explicitly marked, but is only implied, and the translation system must deduce the gender in order to correctly inflect the translation.”
In this paper, Wang et al. devise a template with which a translation system’s gender identification can be evaluated. The authors then test it on German and French:

With the template above, the authors replaced the pronoun with “a set of 200 full names and 200 first names,” then tested for accuracy using a wide array of off-the-shelf translation systems and other custom-trained models.
The results are grim, but not surprising. The authors found that “the NMT system favours male names, with all results far better than for female names, even for the commercial translation systems.” Also of note is that “in general, the larger [the] corpus, the less the name bias is present.” The authors attribute this phenomenon to the fact that a larger amount of data leads to exposure to a wider variety of names, allowing the MT system to “better distinguish their gender.” This isn’t always a solution, however, especially for low-resource languages.
Aside from name biases, Wang et al. also coin the term “sentiment biases,” which have to do more with the kind and nuance of adjectival phrases MT systems resort to when translating. For example, in English, a foreign word meaning “famous” can be translated as “renowned” (a positive connotation) or “notorious” (a negative connotation). For words that can be translated in either a positive or negative nuance, the authors call these words “sentiment ambiguous words”: “a kind of homograph which has both commendatory and derogatory meanings.” Sentiment biases have to do with these kinds of words.
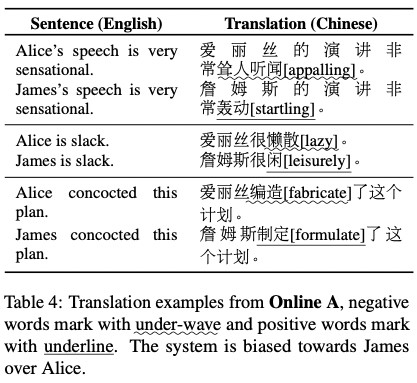

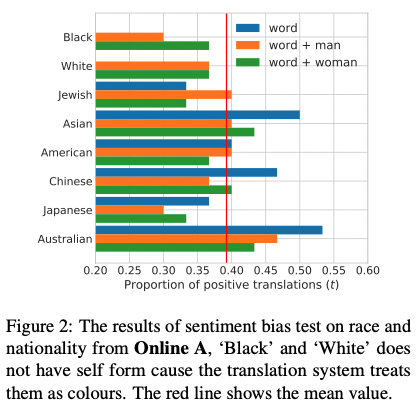
To test sentiment bias, the researchers used English to Mandarin Chinese, as “a cross-language family translation” would be more fruitful for the experiment. Similar to their previous gender bias evaluation of German and French, the authors devised a series of templates, which were fed to the system using a set of gendered names. The results were then evaluated for two evaluation metrics: “word-level positiveness” and “sentence-level positiveness.” On the side, the researchers also used the templates to test for racial and nationality biases, as well as “intersectional racial and gender bias.”
The results prove that there does exist some “evidence of gender bias, such as preferential treatment of actors over actresses, and female politicians and entrepreneurs over their male counterparts.” As for intersectional racial-gender evaluations, “Black man” and “Japanese man” were found to have the most negative connotations.
While not a panacea, the researchers offer a method through which these biases can be mitigated. The main reason for these inequalities, the researchers note, is due to unbalanced training data, which effectively skews the results toward favoring men over women. A simple way to “balance out gender biases is to add a number of female data to balance the ratio of male to female sentences.” Taking into account that “obtaining new data can be difficult… for low-resource languages,” the authors introduce SWITCHENTITY: a data augmentation method that switches names in the training corpus as a means to provide an MT system with more training material using feminine pronouns, articles, and names.
After applying SWITCHENTITY (SE) to three of the custom models mentioned before, the authors checked for translation accuracy. Results of SE application show that SE “has a substantial effect on gender inflection when both translating en->de and en->fr.” This improvement is witnessed across models and datasets, which leads us to conclude that “the SE method has a significant effect of mitigating biases for those models.”
This is not to say that SE is the answer to all our problems. The researchers note that “despite these improvements, the bias remains large.” Furthermore, the extent of this research only pertains to a binary gender system, which omits transgender and non-binary pronouns and names, making for incomplete research into the full breadth of the spectrum of human sexuality. Also of note is the small set of language pairs—it would be interesting to see how this research would play out if applied to low-resource languages.
Under the Morphosyntactic Lens: A Multifaceted Evaluation of Gender Bias in Speech Translation
Authors: Beatrice Savoldi, Marco Gaido, Luisa Bentivogli, Matteo Negri, Marco Turchi
Another long paper regarding gender bias in MT to be accepted by the ACL 2022 is Savoldi et al.’s “Under the Morphosyntactic Lens: A Multifaceted Evaluation of Gender Bias in Speech Translation.” The paper gives a thorough review of the state of MT today in terms of dealing with gender bias, then proposes the natural, gender-sensitive MuST-SHE corpus—designed to overcome the limitations of current evaluation protocols—alongside a three-direction (English-French/Italian/Spanish) evaluation method.
Referencing other researchers such as the likes of Matasović (2004) and Gygax et al. (2019), the writers Savoldi et al. note how “gendered features [of language] interact with the—sociocultural and political—perception and representation of individuals… by prompting discussions on the appropriate recognition of gender groups and their linguistic visibility.” In other words, language—and ensuing machine translation based on language thereof—are deeply tied to the political dimensions of language and the way language both permeates and reflects real-life representations of gender. In that sense, gender bias is a serious, critical problem in the realm of machine translation as MT comments directly on the unequal, gendered landscape of natural languages today.
The writers point out inherent problems in present-day gender bias evaluation benchmarks, which: “i) do not allow us to inspect if and to what extent different word categories participate in gender bias, ii) overlook the underlying morphosyntactic nature of grammatical gender on agreement chains, which cannot be monitored on single isolated words (e.g. en: a strange friend; it: una/o strana/o amica/o).” Current benchmarks simply aren’t precise, nuanced, and robust enough, the authors claim, and fail to account for the grammatical features of gendered languages. A well-functioning evaluation would take into account both part of speech and agreement chains—something that the authors’ very own MuST-SHE corpus takes into account.

Image credits: Under the Morphosyntactic Lens: A Multifaceted Evaluation of Gender Bias in Speech Translation
MuST-SHE is notable in that it differentiates between 6 parts-of-speech categories: “i) articles, ii) pronouns, iii) nouns, and iv) verbs,” with adjectives distinguished between “v) limiting adjectives with minor semantic import that determine e.g. possession, quantity, space (my, some, this); and vi) descriptive adjectives that convey attributes and qualities, e.g. glad, exhausted.” Upon utilizing MuST-SHE and evaluating performance based on the corpus, the researchers discovered that, “while all POS are subject to masculine skews, they are not impacted to the same extent.”
Unlike many papers, the authors of “Under the Morphosyntactic Lens” finish the paper with an “impact statement,” in which they discuss the broader impact of the research. The authors rehash the dangers of gender bias in MT, citing that the behavior of Mts to “systematically and disproportionately [favor] masculine forms in translation” is “problematic inasmuch it leads to under-representational harms by reducing feminine visibility.” Next, the authors posit that this research paves the way for future NLP and MT research, as “Under the Morphosyntactic Lens” creates a space in which to ponder upon and renegotiate the depth and extent to which data and models should be sensitized to gender nuances.
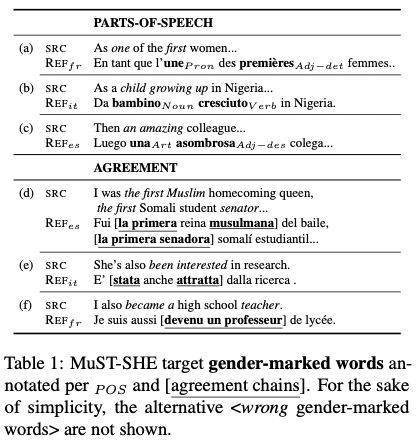
Image credits: Under the Morphosyntactic Lens: A Multifaceted Evaluation of Gender Bias in Speech Translation
These two papers are two of few papers published on gender bias in MT, among 604 long papers that were accepted by the ACL 2022. While the number is small, these two papers raise awareness of the importance of combating gender bias—alongside other types of biases—in machine translation.
References
https://slator.com/here-are-the-best-natural-language-processing-papers-from-acl-2022/
https://aclanthology.org/2022.acl-long.184.pdf
https://aclanthology.org/2022.acl-long.127.pdf