Kinyarwanda Comes to the Forefront at ACL 2022
In our previous blog post, we introduced ACL 2022—the 60th Annual Meeting of the Association for Computational Linguistics—and two papers featured there: one on the disambiguation bias benchmark DiBiMT and another on low-resource speech synthesis on Indigenous languages in Canada. Today, we’re adding one more to the list of research that caught our attention. Antoine Nzeyimana of the University of Massachusetts Amherst and Andre Niyongabo Rubungo of the Polytechnic University of Catalonia won Best Linguistic Insight Paper with this research, titled “KinyaBERT: a Morphology-aware Kinyarwanda Language Model.”
As can be inferred by the title, the paper introduces a two-tier BERT architecture that, unlike previous pre-trained models, can take advantage of a morphological analyzer to translate low-resource, morphologically complex languages like Kinyarwanda. Past research in natural language processing has focused majorly on English, Chinese, and European languages spoken by economically prevalent powers, which has “exacerbated the language technology divide between the highly resourced languages and the underrepresented languages.” The authors note that this effectively hinders NLP research, as it is “less informed of the diversity of the linguistic phenomena.”
KinyaBERT, then, is all the more relevant. A “simple yet effective two-tier BERT architecture for representing morphologically rich languages,” KinyaBERT paves the way for morphologically rich, underresourced languages previously ignored by most NLP research. And the results are outstanding; whereas previous models are “sub-optimal at handling morphologically rich languages,” KinyaBERT outperforms baseline scores by 2 to 4.3%, proving that low-resource language translation is still viable on pre-trained language models.
The authors start off by noting that “recent advances in natural language processing (NLP) through deep learning have been largely enabled by vector representations (or embeddings) learned through language model pre-training.” BERT is one such example; it is pre-trained on vast amounts of text, then fine-tuned on downstream tasks, which greatly enhances performance on many NLP tasks. To this date, models pre-trained on monolingual data still outperform multilingual models. With all this said, KinyaBERT is an effort to utilize the advantages of a model pre-trained on monolingual data, except with a morphologically rich language such as Kinyarwanda.
There are a number of reasons why previous models don’t work as well for morphologically complex languages. For one, models like BERT use “statistical sub-word tokenization algorithms such as byte pair encoding (BPE),” which are “not optimal for morphologically rich languages” due to linguistic characteristics such as morphological alternations and non-concatenative morphology. The table below shows how both monolingual BPE models and multilingual BPEs fail, after being trained on 390 million tokens of Kinyarwanda text, to identify the correct morpheme:

Image credits: “KinyaBERT: a Morphology-aware Kinyarwanda Language Model.”
Many factors complicate the Kinyarwanda language (like all other languages, Kinyarwanda is complex, although the reasons for its complexity are not as known as those of European languages). For example, Kinyarwanda has 16 noun classes, and “modifiers (demonstratives, possessives, adjectives, numerals) carry a class marking morpheme that agrees with the main noun class.” Furthermore, “the verbal morphology also includes subject and object markers that agree with the class of the subject or object”: markers that are used by “users of the language to approximately disambiguate referred entities based on their classes.”

Image credits: “KinyaBERT: a Morphology-aware Kinyarwanda Language Model.”
This agreement property is utilized by the authors’ unsupervised POS tagger. Before pre-training the model, KinyaBERT must be fitted with a morphological analyzer that takes into account all word types that can be inflected in the Kinyarwanda language. Afterward, the authors compose a complex speech tagging algorithm that measures syntactic agreement and estimates first order transition measures.
Once all the tagging and analysis are complete, the morphology encoder takes over. The encoder is “applied to each analyzed token separately in order to extract its morphological features,” which are then “concatenated with the token’s stem embedding to form the input vector fed to the sentence/document encoder.” Shown below is a diagram of the architecture of KinyaBERT:
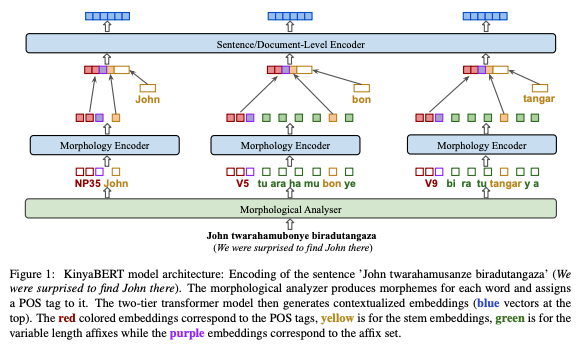
Image credits: “KinyaBERT: a Morphology-aware Kinyarwanda Language Model.”
KinyaBERT is then pre-trained using 2.4 GB of Kinyarwanda text comprised of 390 million tokens/words and 16 million sentences taken from 840,000 documents and articles. Upon evaluating the pre-trained model using the GLUE benchmark, the KinyaBERT achieves a “4.3% better average score than the strongest baseline.” For the named entity recognition task, the KinyaBERT achieves a “3.2% better average F1 score than the strongest baseline.”
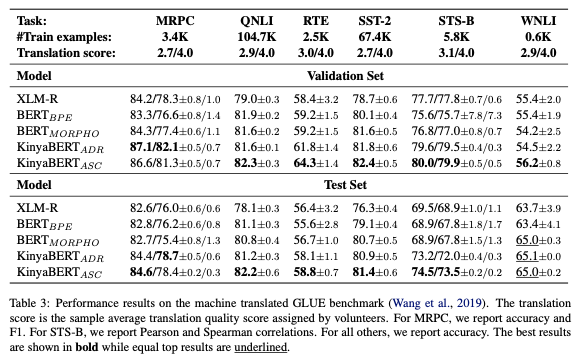
Image credits: “KinyaBERT: a Morphology-aware Kinyarwanda Language Model.”
Overall, KinyaBERT is yet another step in the right direction for machine translation and natural language processing. Many research fails to take into account that the omission of low-resource, underrepresented languages can be detrimental to NLP research in that such omission skews the linguistic landscape. “There are very few works on monolingual PLMs [pre-trained language models] for African languages…” the authors write. “we aim to increase the inclusion of African languages in NLP community by introducing a PLM for Kinyarwanda.” This paper is significant not only for these linguistic reasons but also because it enriches BERT research and architecture, paving a path for other underresourced languages to follow suit.
Alongside Pine et al.’s “Requirements and Motivations of Low-Resource Speech Synthesis for Language Revitalization” covered in our last post, this paper on KinyaBERT makes up a small but critically essential part of NLP and MT research that sheds a sorely needed spotlight on underresourced languages. It’s important that NLP research heed and remain open to the possibilities that previously disregarded languages bring to the table.
Alongside papers, both long and short, the ACL 2022 hosted keynote speeches and panels on a wide variety of topics. Particularly relevant to the topic of underresourced language representation was the keynote panel on “supporting lingusitic diversity,” whose panelists included researchers and speakers of the following languages: Seneca (USA), Minangkabau (Indonesia), Creole languages, Irish, Wixaritari (Mexico), and Luo and Kiswahili (Kenya).
The panel poses important questions: “How do the tools and techniques of computational linguistics serve the full diversity of the world’s languages? In particular, how do they serve the people who are still speaking thousands of local languages, often in highly multilingual, post-colonial situations?” Here are other questions covered by the panel, based on the following topics:
Diverse Contexts. What is the situation of local languages where panel members are working? Are there multiple languages with distinct functions and ideologies? What are the local aspirations for the future of these languages. How are people advocating for language technology on the ground? How did the work begin? What does success look like?
Understanding Risks. Do the people who provide language data fully understand the ways their data might be used in future, including ways that might not be in their interest? What benefit are local participants promised in return for their participation, and do they actually receive these benefits? Are there harms that come with language standardisation? What principles of doing no harm can we adopt?
New Challenges. How can we provide benefits of text technologies without assuming language standardisation, official orthography, and monolingual usage? When working with local communities, do we always require data in exchange for technologies, or is a non-extractive NLP possible? How do we decolonise speech and language technology? At the beginning of the International Decade of Indigenous Languages 2022–2032, we ask: how do we respond as a community, and how can our field be more accessible to indigenous participation?
Going forward from here, the inclusion of underresourced languages is essential to the integrity and future of NLP research, and it is important that researchers ask themselves these questions in regard to the extent of languages covered. Issues concerning which languages are chosen to be represented in certain academic research, or for what purposes these languages are utilized: these are questions that are closely intertwined with the history and politics of such languages. In that sense, discussion around language should be intentional and deliberate.
“KinyaBERT: a Morphology-aware Kinyarwanda Language Model” seeks to do exactly that: create spaces for intentional and deliberate discussion around the supremacy of European languages in the NLP discourse. KinyaBERT actively dismantles and combats the prevalency of European languages, shifting the discourse into a more equal, balanced dynamic in which underresourced languages can voice their presence and existence.
References
https://arxiv.org/abs/2203.08459
https://www.2022.aclweb.org/keynote-speakers