New Speech-to-Speech Translation (S2ST) Paradigms for Spoken Languages
Earlier in the month, Meta AI highlighted an area of its research dealing with speech-to-speech translation. In an article titled “Advancing direct speech-to-speech modeling with discrete units,” Meta AI researchers Ann Lee and Juan Pino alongside product manager Jeff Wang and product designer Ethan Ye briefly share Meta’s current research in the speech-to-speech translation field. Building on previous research, the current project is “the first direct S2ST system trained on real-world open sourced audio data instead of synthetic audio for multiple language pairs.”
Compared to text translations—which have been around for millennia—speech-to-speech translation is a relatively new field of study, made available by recent developments in automatic speech recognition (ASR), voice synthesis (TTS), and machine translation (MT). One of the first demonstrations of general speech translation was in 1999 when researchers from five different countries demonstrated a rudimentary version of speech-to-speech translation in French, English, Korean, Japanese, and German as part of the C-STAR II consortium. The same year, NEC succeeded in developing “Tabitsu,” an automatic speech-to-speech translation software for notebook PCs equipped with 50,000 Japanese and 25,000 English words related to travel and tourism.
What makes Meta AI’s foray into speech-to-speech translation different is that, unlike previous research, it aims to dramatically simplify the system process—hence, the title: direct speech-to-speech modeling. Previous models take a “cascaded approach,” meaning they first transcribe the spoken phrase into text, which is then machine-translated then output into speech again using text-to-speech (TTS) synthesis. A majority of research focuses on this cascaded system, with many researchers succeeding in streamlining the process or increasing the efficiency of each part of the setup. Nascent research in the past couple of years has given rise to more innovative approaches, such as the Translatotron—which “directly translates mel-spectrogram of the source speech into spectrogram features of the target speech”—and Kano et al.’s 2021 proposal to “build a single deep-learning framework by pre-training ASR, MT and TTS models separately and connecting them with Transcoder layers.”
Much like these new paradigms for S2ST, Meta AI’s research tries to avoid relying on intermediate text generation and thus cut out much of the cascading, intermediary steps. Meta instead opts for “discrete units,” which more efficiently handles the process, as it can “disentangle linguistic content from prosodic speech information.” Below is a diagram of how the model works with discrete units:
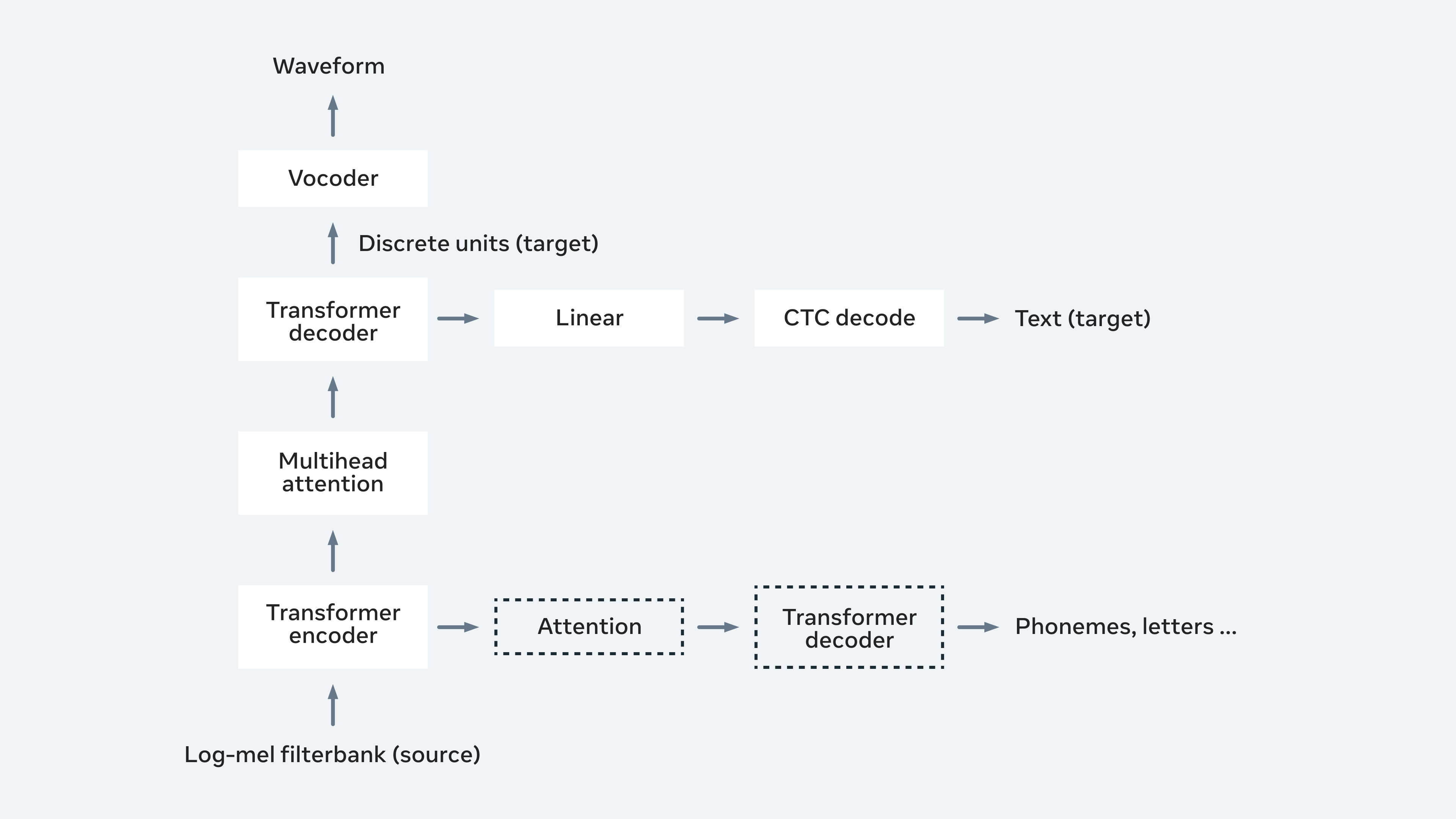
A diagram depicting the structure of Meta’s direct S2ST model using discrete units. Image credits: https://arxiv.org/abs/2107.05604
Another difference from the previous models is that Meta incorporates newly available, real-world S2ST data in model training. S2ST doesn’t have a big enough parallel training dataset, meaning it relies on TTS to “generate synthetic target speech for model training.” Meta, in “Textless speech-to-speech translation on real data” was able to utilize real data from the VoxPopuli S2S data and the automatically mined S2S data.
So what do the results look like? Is Meta AI’s discrete unit-based any more efficient or accurate than previous models? Testing their model on the Fisher Spanish-English speech translation corpus (which consists of 139,000 sentences of Spanish conversations and corresponding Spanish/English text transcriptions), the researchers found that the framework reaches 6.7 BLEU compared to a previous model—an improvement. When the model is trained without text transcripts, it is comparable to models that are trained with text supervision but predict spectrograms.
Meta’s direct speech-to-speech model with discrete units provides not just better translation quality, but also heightened efficiency in terms of runtime, FLOPS, and max memory. With its bigger training data and new paradigm, Meta’s new model works even better for unwritten languages, which have previously been largely ignored due to the fact that it is near impossible to translate without text transcriptions.
This research is part of Meta AI’s efforts to expand its reach so that more languages are covered by the translation services the company offers. Alongside this research are other projects aimed to democratize language prevalency in text translations—such as its M2M-100 model, the first multilingual machine translation model that translates between 100 languages without relying on English data—as well as its No Language Left Behind project and Universal Speech Translator initiative.
References
https://arxiv.org/abs/2107.05604
https://ai.facebook.com/blog/advancing-direct-speech-to-speech-modeling-with-discrete-units/
http://www.nec.co.jp/press/en/0401/0601.html
https://www.isca-speech.org/archive_v0/archive_papers/icslp_2000/i00_4412.pdf