Reimagining Machine Translation with MIT’s Hallucinatory VALHALLA
As we write this, the world is reeling from DALL-E 2: an OpenAI artificial intelligence program that, in the simplest terms, draws what you say. The Eiffel Tower enjoying a skinny dip? You got it. Midsommar, but make it cyberpunk? You got it. On Twitter, TikTok, and Instagram, people are sharing their craziest inputs as DALL-E turns it into a believable, hilarious work of art, like these picture of Winnie the Pooh robbing a 7-Eleven store:
Image credits: https://twitter.com/weirddalle/status/1538103168088817664
Or these pictures of a dumpster fire, but painted by Monet:

Image credits: https://twitter.com/weirddalle/status/1537846400570077184
DALL-E uses a 12-billion parameter version of the GPT-3 Transformer model—a natural language processing model that gives DALL-E its trademark wealth of knowledge and robustness to handle the weirdest of commands. It also uses an autoregressive transformer—in which the model takes past values and applies them to create new values. That’s how it understands input such as “Mickey Mouse and Donald Duck in a Mexican standoff”—because it takes from its wide range of past values (“Mickey Mouse,” “Donald Duck,” “Mexican standoff”) and merges it into a new value. This is a grossly simplified explanation of what DALL-E actually does.
Last month, on May 31, researchers at US San Diego, IBM, and MIT have jointly published a research paper on VALHALLA, a “visual hallucination framework” and a close cousin of DALL-E. While the structure and framework of DALL-E make it suitable for creating artistic, creative pieces of visual media, VALHALLA utilizes visual modes to try and improve machine translation. While not as vivid or concrete as DALL-E’s manifestations, VALHALLA also predicts discrete “hallucinated visual representations”; combined with the input text, the picture is then used to figure out the target translation. To the best of the researchers’ knowledge, VALHALLA is the first work that “successfully leverages an autoregressive image transformer jointly with the translation transformer to hallucinate discrete visual representations.”
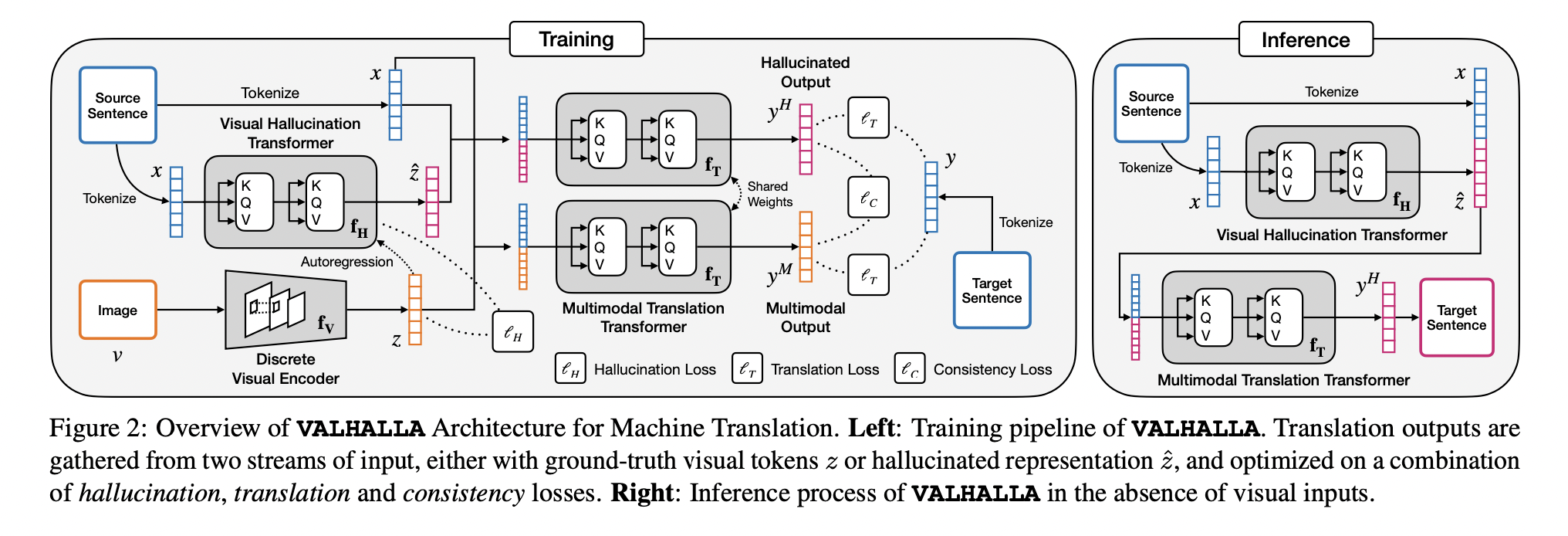
An overview of VALHALLA’s structure. Image credits: https://arxiv.org/abs/2206.00100
In previous blog posts, we’ve spoken of machine translation and its numerous iterations and paradigms. From its rules-based paradigm, MT has developed into statistical MT models, from which it has now evolved into neural network-based models. VALHALLA continues the tradition of reforming paradigms; this time around, machine translation is multimodal—meaning it utilizes a variety of modes, such as text and pictures.
After all, even the best of previous models—the neural network-based multilingual models come to mind—currently are mostly text-only; the ones that do utilize visual context usually “require manually annotated sentence-image pairs as the input during inference.” In regard to the former type, VALHALLA researchers cite that such systems “lack any explicit grounding to the real world.” As such, “there has been a growing interest in developing multimodal MT systems that can incorporate rich external information into the modeling process.”
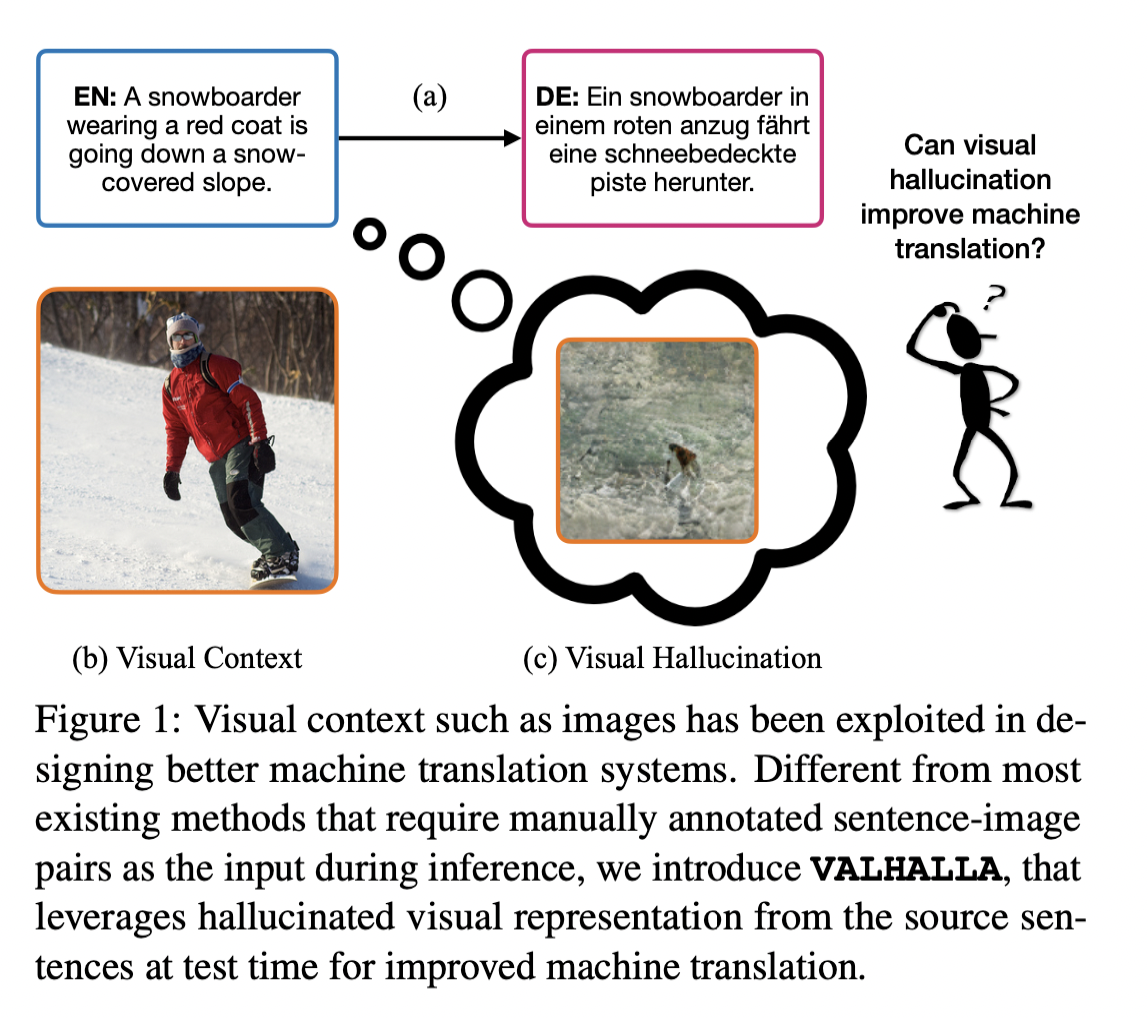
An illustration of VALHALLA’s visual hallucination technique. Image credits: https://arxiv.org/abs/2206.00100
As in the figure above, it is important to note that “the underlying visual perception [of a situation in the physical world] is shared among speakers of different languages.” The above sentence—“A snowboarder wearing a red coat is going down a snow-covered slope” shares the same visual perception as “Ein snowboarder in einem roten anzug fährt eine schneebedeckte piste herunter.”
VALHALLA has exhibited great improvements over previous models. Using three public datasets—Multi30K, Wikipedia Image Text (WIT), and WMT2014—the researchers rate VALHALLA’s performance, and the results are quite astounding. When evaluated using Multi30K, VALHALLA “significantly outperforms the text-only baselines on all three test sets.” Furthermore, VALHALLA “outperforms all compared methods, achieving best BLEU and METEOR scores under both multimodal and text-only translation settings.” VALHALLA performs exceptionally across the board in all datasets.
The ramifications of VALHALLA are both exciting and hopeful. According to its performance review when evaluated with the WMT dataset, VALHALLA “outperforms all the compared methods in both well- and under-resourced settings. The improvements over text-only baseline are more significant in under-resourced scenarios, which is of significant practical value.” The report also dedicates a good amount of analysis to how VALHALLA performs well even when translating under limited textual context.
With the advent of natural language processing as it breaches the sphere of visual media, it’s time to welcome these changes to machine translation paradigms. Such is the beauty of cutting-edge scientific developments: research like this allows us to venture outside the comforts of what we once thought science should be and imagine new frameworks and concepts through which we can reform tired structures. All this leads to the eventual democratization of information and communication, we hope; even the most neglected of languages will, soon enough, have a chance to be heard alongside widely spoken lingua francas.
At the same time, we are wary as to the feasibility of these new developments and techniques. When will they be readily available for application in practical functions? Or is this all part of a vague vaporwave trend—grandiose notions of technology bridging gaps when, in reality, we find ourselves just as incapable of communicating ourselves to one another as in the olden days?
But the realm of machine translation proves to be, time after time, rife with positive, groundbreaking change that renegotiates our connection to one another and language. We hope that VALHALLA, like its preceding paradigms and developments, will revolutionize the way we think of translation and language.
References
https://arxiv.org/abs/2206.00100
https://news.mit.edu/2022/hallucinating-better-text-translation-0606
https://twitter.com/weirddalle