Taking Pathways to a New Level with the Pathways Language Model (PaLM)
A few weeks ago, we shared some exciting news about Google’s latest foray into artificial intelligence. Their new, exciting development? An AI architecture called Pathways, which, unlike previous AI systems that are designed for specific purposes, can more efficiently and innovatively handle tasks with a flexibility never before seen in artificial intelligence.
Earlier this month, Google software engineers Sharan Narang and Aakanksha Chowdhery—with a number of other Google researchers—introduced the Pathways Language Model (PaLM): a scaled application of Pathways to natural language processing. PaLM is a 540-billion parameter, dense decoder-only Transformer model that has been trained with the Pathways system, utilizing 6,144 chips and lots and lots of data samples. According to Slator’s Anna Wyndham, this makes PaLM larger than Microsoft and NVIDIA’s Megatron-Turing NLG, DeepMind’s Gopher, and OpenAI’s GPT-3.
And the results are astounding; the researchers “evaluated PaLM on hundreds of language understanding and generation tasks, and found that it achieves state-of-the-art few-shot performance across most tasks, by significant margins in many cases.”
The history
Recent years have seen the rise of larger neural networks trained for comprehension and language generation. OpenAI’s GPT-3 was the first model to show that large language models (LLMs) can be utilized for few-shot learning (learning with limited data sets) to great effect without the need for “large-scale task-specific data collection or model parameter updating.” Microsoft/NVIDIA’s Megatron-Turing NLG and DeepMind’s Gopher have shown even more outstanding results, as they exhibit more efficient processes and more accurate results. But Narang and Chowdhery note that “much work remains in understanding the capabilities that emerge with few-shot learning as we push the limits of model scale.” In other words, what are large language models capable of if we push them to their very limits?
How they do it
PaLM is an answer to that question, to the unforeseen capabilities of large language models to set new standards in artificial intelligence and language processing. The researchers used data parallelism across two Cloud TPU v4 Pods, which is a significant rise in scale compared to previous LLMs, most of which were trained on a single TPU v3 Pod or multiple TPU v3 Pods. Thanks to this parallelism strategy, as well as a “reformulation of the Transformer block that allows for attention and feedforward layers to be computed,” PaLM boasts a training efficiency of 57.8%, which the researchers claim to be “the highest yet achieved for LLMs at this scale.”
As for data, the researchers trained PaLM using both English and multilingual datasets including high-quality web documents, books, Wikipedia, conversations, and GitHub code. Also of note is the addition of a “lossless” vocabulary, which “preserves all whitespace (especially important for code), splits out-of-vocabulary Unicode characters into bytes, and splits numbers into individual tokens, one for each digit.” In other words, PaLM is geared towards efficient data management and handling, so as to perform better over a wide range of areas.
The results
PaLM exhibits what the researchers call “breakthrough capabilities on numerous very difficult tasks.” The researchers evaluated PaLM on 29 frequently-used English natural language processing tasks, such as question-answering tasks, cloze and sentence-completion tasks, Winograd-style tasks, in-context reading comprehension tasks, common-sense reasoning tasks, SuperGLUE tasks, and natural language inference tasks. It’s also remarkable that PaLM has also performed well on multilingual NLP benchmarks, including translation, despite the fact that a mere 22% of the training corpus was in a language other than English. The following chart depicts PaLM’s performance improvement compared to previous state-of-the-art (SOTA) systems:
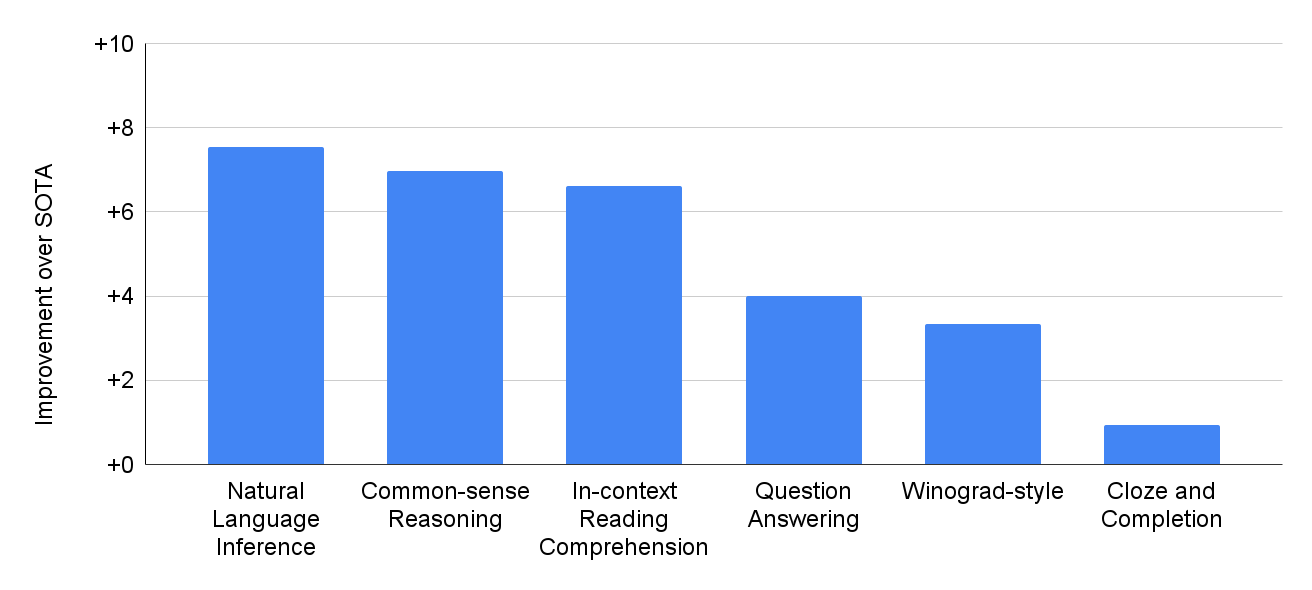
The researchers also charted the scaled improvements of PaLM using the Beyond the Imitation Game Benchmark (BIG-bench), a suite of more than 150 new language modeling tasks. Compared to Gopher and Chinchilla, PaLM showed outstanding results, outperforming the two with the sheer power of its parameters. Here is the chart that compares the three systems:
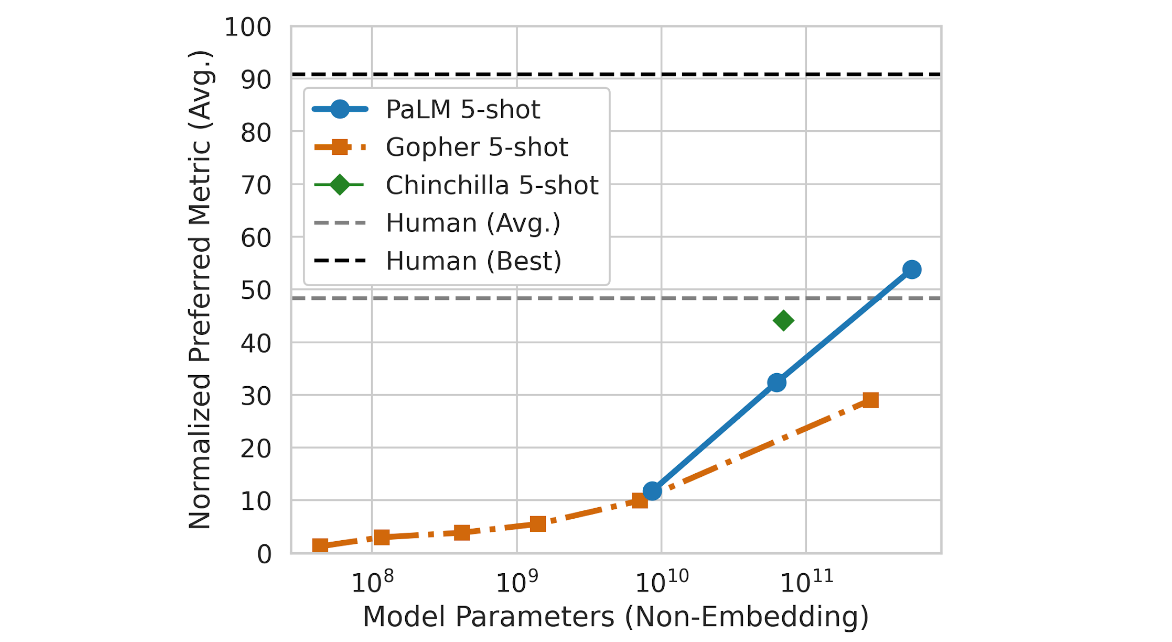
The researchers note, however, that “PaLM’s performance as a function of scale follows a log-linear behavior similar to prior models, suggesting that performance improvements from scale have not yet plateaued.” Furthermore, at 540 billion parameters, PaLM actually outperforms the average performance of humans. All this is to say that PaLM is wonderfully effective at what it does, and that it knows no bounds—the ceiling is nowhere to be seen for this one.
The tasks
The researchers showcase some of the feats of PaLM, starting with its “impressive natural language understanding and generation capabilities on several BIG-bench tasks.” They note how PaLM is able to differentiate between cause and effect, comprehend conceptual combinations in contexts, and—get this—even guess a movie based on a series of emojis.

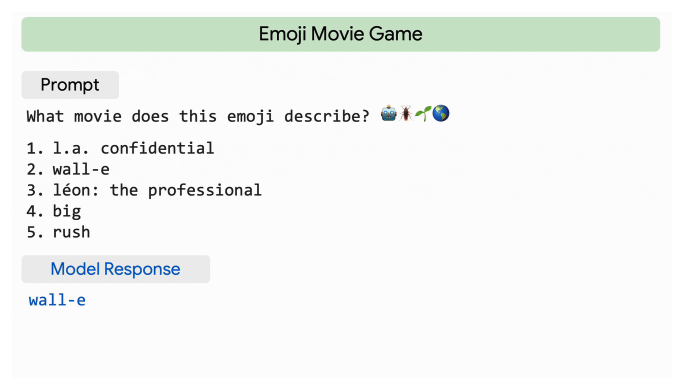
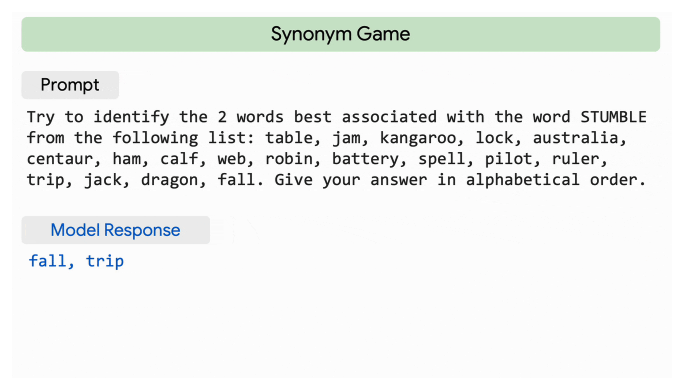


PaLM is also capable at reasoning tasks, thanks to its chain-of-thought prompting. This means that PaLM excels at multi-step arithmetic and common-sense reasoning compared to previous LLMs. This following comparison shows how PaLM drastically outperforms its previous counterparts:

With 8-shot prompting, PaLM succeeds in solving 58% of the problems, 3% higher than the prior top score of 55%. It is also only 2% lower than the 60% average of problems solved by 9- to 12-year-olds, who are the supposed target audience for the questions solved by PaLM.
But what is perhaps most impressive about PaLM’s results is its ability to “generate explicit explanations for scenarios that require a complex combination of multi-step logical inference, world knowledge, and deep language understanding.” When given a novel joke it has never seen, PaLM provides a high-quality explanation, like this example:
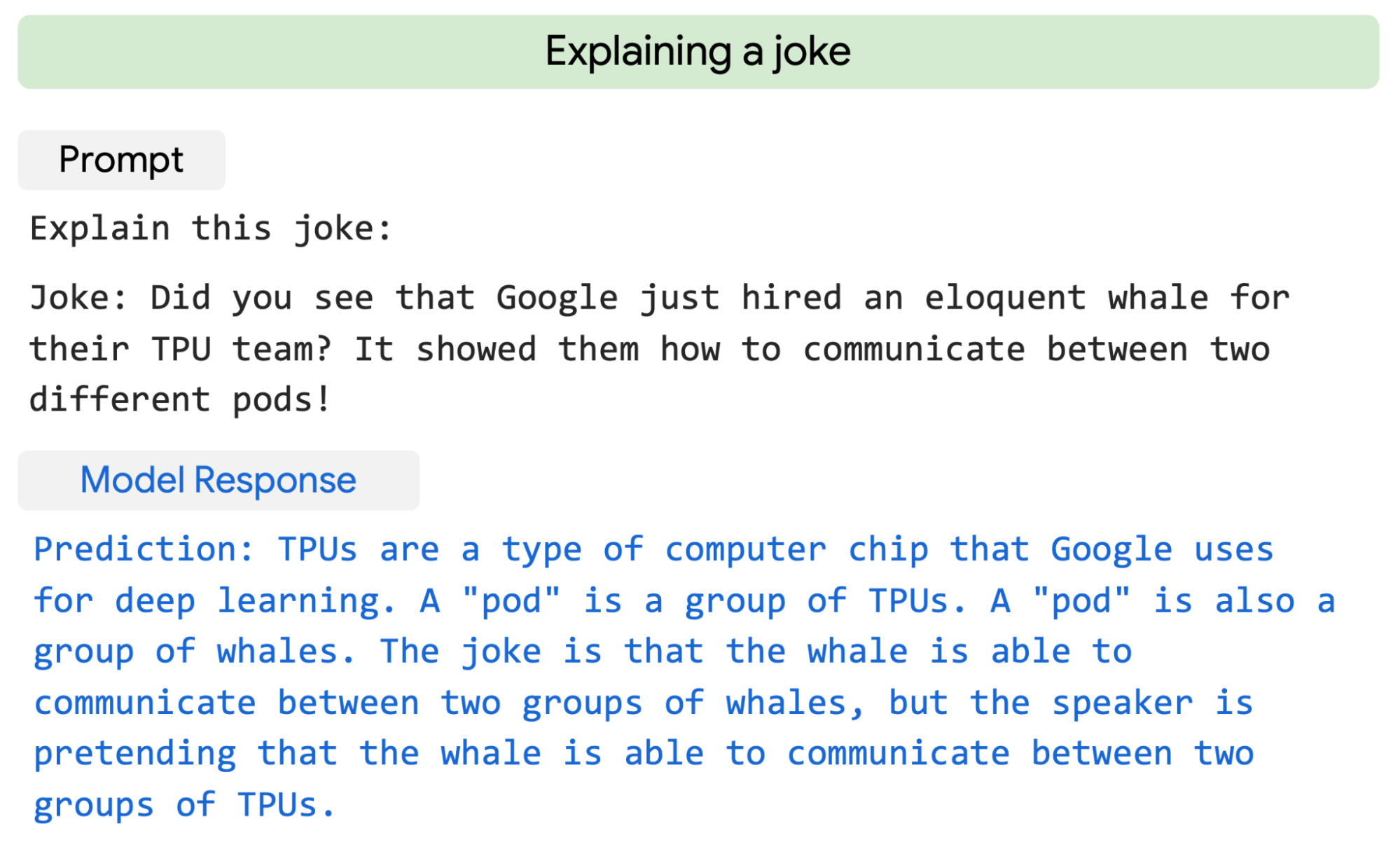
Lastly, despite the fact that only 5% of its pre-training dataset was code, PaLM exhibits strong performance in coding tasks, rivaling the prowess of the fine-tuned Codex 12B while using 50 times less Python code for training. The researchers attribute this phenomenon to earlier findings, which state that “larger models can be more sample efficient than smaller models because they transfer learning from both other programming languages and natural language data more effectively. Here are some examples of the coding problems PaLM solves with ease:
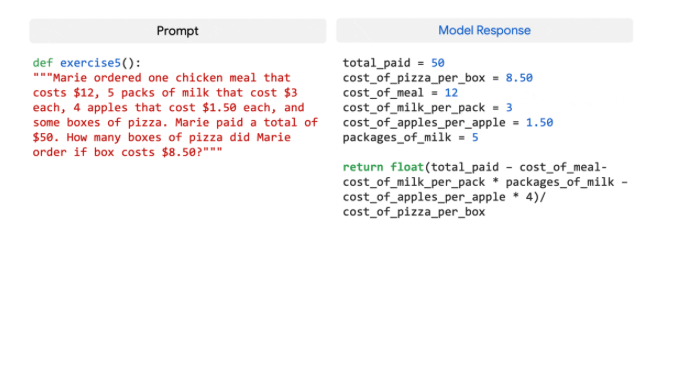


Ethical considerations
While all these new development and achievements are remarkable and exciting, researching artificial intelligence and language models should be examined and treated with care, given that their learning process relies heavily on taking in information available on the web. The developers of PaLM took great care to document their ethical considerations and processes, keeping a “datasheet, model card and Responsible AI benchmark results” and carrying out “analyses of the dataset and model outputs for biases and risks.” In the words of Narang and Chowdhery:
While the analysis helps outline some potential risks of the model, domain- and task-specific analysis is essential to truly calibrate, contextualize, and mitigate possible harms. Further understanding of risks and benefits of these models is a topic of ongoing research, together with developing scalable solutions that can put guardrails against malicious uses of language models.
PaLM showcases what LLMs are capable of once they’re pushed to their limit. With its more efficient, smarter processes, the conscience of language models is starting to resemble that of humans. Make sure to check out the Google blog post and their paper, in which they go into more detail about their research processes.
References
https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
https://arxiv.org/pdf/2204.02311.pdf
https://slator.com/the-great-language-model-scale-off-googles-palm/